

明略科技吳明輝:大中型企業如何落地AI大模型?
發佈時間:2024-06-11 10:15:58 | 來源:中國網科學 | 作者: | 責任編輯:科學頻道
為了讓更多企業拿到大模型的船票,明略科技推出小明助理Copilot一站式大模型AI智慧助理,以瀏覽器插件形式兼顧PC/移動端網頁等産品形態,開箱即用,且具備聯網搜索功能,通過ChatPDF、對照式翻譯、行銷文案生成和豐富好用的Agent,讓企業輕鬆用上大模型。
有了AI工具,又要如何産生生産力?近日,明略科技創始人吳明輝做客混沌學園,帶來主題為《AI如何賦能職場人——大模型落地企業方法論》的精彩分享,以下是分享內容核心整理:
一、我的個人經歷:充分擁抱新技術紅利
2022年,當我在北大寫博士論文的時候,才發現自己的綜合資格考試報告白寫了,很多知識都發生了更新。今天在讀的AI領域博士非常慘,因為以往全世界所有從事人工智慧一年的工作量,都不及今天一週的工作量大,大家如果不抓緊做出課題發表出去,基本上沒有畢業的機會。

今天,我要同大家分享很重要的一個觀點,就是不要著急。電腦剛剛出現的時候,每個人都説要從娃娃抓起,那時大家就很焦慮。事實上,我身邊許多在世界500強企業工作的CEO,幾乎都是跟我同齡時期才開始寫代碼的。所以,每一項新技術的出現都是有紅利的,最終大家也一定都會使用到,只是接觸早的人會比別人多一些機會和時間。如同《異類》一書中提出的1萬小時定律,只要比別人多花一些時間做某件事情,未來就有機會享受到某領域的競爭紅利。我創辦的公司名為明略科技,早期叫做秒針系統,是我在北大讀研究生時候創辦的,開始是做網際網路大數據的用戶分析,後來轉型做廣告分析。我們是國內最早用分佈式計算系統處理海量用戶行為的數據公司,這也成就了今天我們在國內網際網路廣告數據分析的江湖地位。

大家都很熟悉彭博社,彭博社是全世界最大的金融資訊服務商,而秒針是中國最大的廣告領域資訊服務商,兩者頗有淵源。彭博社的創始人邁克爾·布隆伯格創業初期,立志將電腦賣給每一位投資基金,希望幫助大家快速地獲取網際網路上的金融資訊,這也成就了彭博社今天在全球金融資訊服務領域的霸主地位。所以,很多公司都在擁抱新技術,它們可能是將某一項新技術用到了極致,或者是第一個使用新技術從而顛覆了上一代産品,最終走出了新的曲線。
二、大模型是當下的最大機會
為什麼要研究大模型?因為這是當下最大的機會,這是我的切身感受。明略科技在過去十幾年時間裏發展得很順利,但是過去三年中,資本市場發生了非常大的變化,整個商業邏輯也發生了改變,我們不得以也得裁員。2023年一年時間裏,我每天都在思考如何帶領團隊突破困局,如何提升士氣,在我面前非常大的一個機會就是大模型。我們團隊研究大模型也經歷了非常曲折的過程。開始的時候我每天看Paper,然後轉發到員工群中,大家的反映很平常,時間一長甚至沒有人回應了。有一天我突然意識到,天天喊大模型是沒有用的,我自己都沒有真正地用好大模型,所以我註冊了GPT,開始真正使用大模型,並帶領團隊做了一個能夠幫助大家更好使用GPT的小工具,叫做“小明助理”,員工使用後的反響非常好。
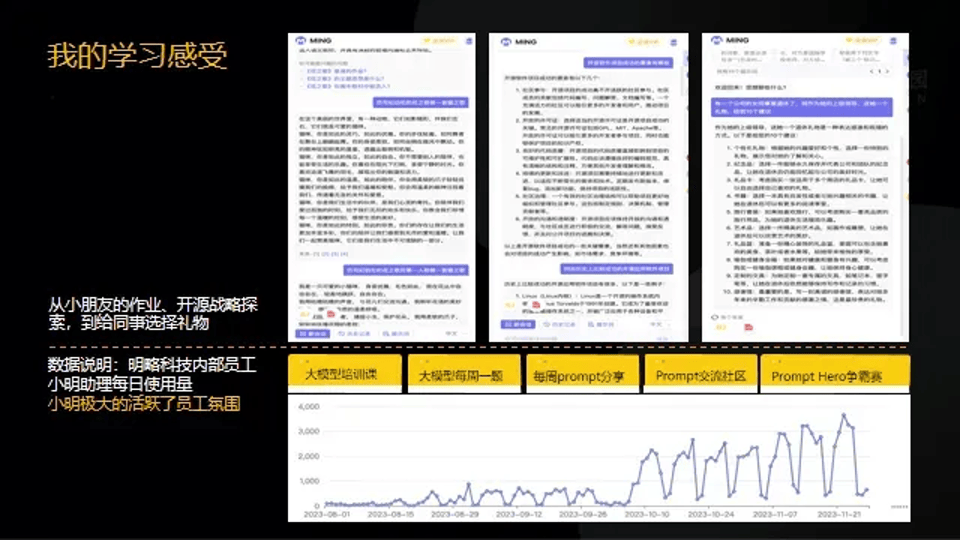
2023的10月,公司還舉辦了駭客馬拉松大賽,我在場上向大家分享了十一期間使用大模型的經歷,包括帶著女兒用GPT寫作業,用大模型思考公司戰略,以及向大模型詢問為退休同事準備禮物的建議,大模型的確給了我很多啟發。我把使用案例分享給團隊後,大家都驚訝地發現“小明助理”的用途如此廣泛。今年,公司員工已經做到了廣泛使用大模型,平均每個員工一天使用10次以上,大家不僅可以用GPT解決工作生活中遇到的一些問題,甚至可以放到自己的生産環境中用於提升生産效率,可以説,公司團隊絕大多數的同學都已經拿到大模型的船票。
三、AI大模型的本質是一個函數,小朋友都懂
大家都很容易理解函數公式y=f(x)。大模型本質上就是一個函數,就是要設計、訓練、學習出來一個函數。人工智慧大模型領域常見的幾種任務,比如語音識別,就是把一個聲音的波形文件轉化成一段文字,語音識別的函數x就是波形文件,y就是轉寫的文字。比如圖像識別,圖像識別的函數x就是照片,更高級的函數x可能是視頻,它的y就是識別的任務目標。GPT其實也是一個函數,GPT的x就是Prompt,y就是給予你的回復,GPT本質上仍然是一個函數。從這個角度看,所有的人工智慧都是一個函數。
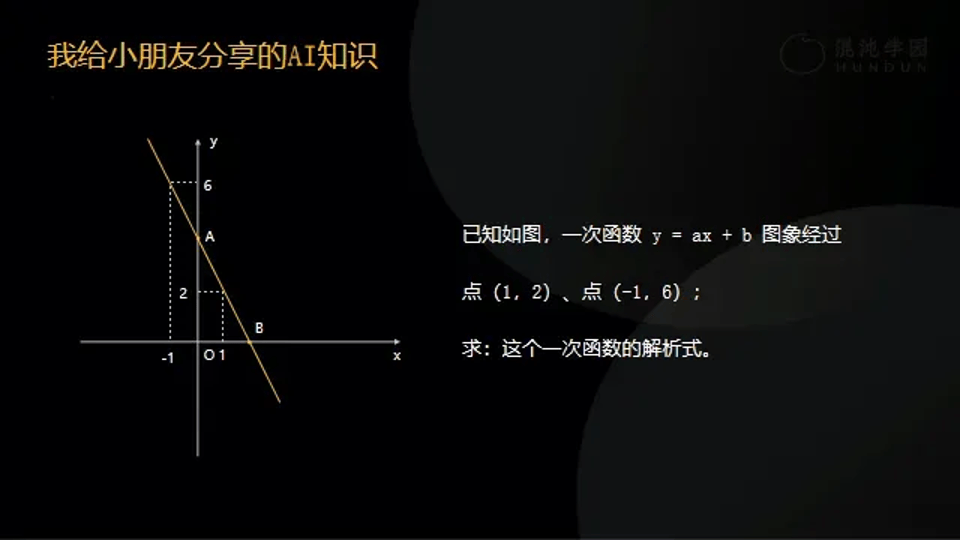
大家在中學期間學習的第一個函數就是線性函數,y=ax+b,當你知道函數的兩個點,就可以得出a和b。將這個函數解出來之後,再帶進去一個新的x,就可以直接求出y了,這是我們學函數的核心目的,找出x和y之間的關係,這也是今天AI在做的事情。AI就是我們做任何一個人工智慧領域的任務,這個任務本身就是一個函數。這裡面的(1,2)和(-1,6)是什麼?就是訓練的數據。

當然,GPT的函數要比以往的函數複雜很多,現在全世界最火的語言模型是GPT3.5和GPT4.0,GPT3.5有1750億個參數,GPT4.0估計有上萬億個參數,這個參數就是線性函數裏面的a和b。由此可見,GPT非常厲害的,它列了一個有千億甚至上萬億個參數的函數,然後代入了大量的數據和點,最後把裏面的參數解了出來。我認為OpenAI是一家非常偉大的公司。OpenAI公司的創始人是Ilya,之後是前YC的總裁SamAltman,很多人在討論,到底是Ilya重要還是Altman重要,因為OpenAI的核心演算法都是Ilya帶著研發團隊做的,但是我認為Altman更重要一些,因為他解決了一個核心問題,即錢的問題。解一個萬億參數的方程,少則幾千萬美金,多則幾億美金。Altman的偉大之處,在於他可以讓有錢的投資人敢於投資未知的事業,並且最終將方程式解了出來,這是一個改變世界、改變人類的偉大發明。
四、AI在企業落地:大模型産生生産力的根本邏輯
回到企業視角,明略科技是做ToB業務的,在同其他企業CEO、CIO、CMO聊天的時候,我發現大家對於大模型的出現都感到很興奮,很多公司都建立了人工智慧小分隊,但嘗試幾次後發現效果並不理想。有一些人認為是因為國內的模型不行,他們嘗試使用國外的,結果也並不好。我認為,一個想真正落地大模型的企業,如果還保持著上述思路,你與大模型就今生無緣了,因為大模型並不是參數越多,推理能力越強,越能解決自身的業務問題的。
現在,OpenAI已經把參數做得非常高了,它擁有的是網際網路上的通識知識,如果訓練得足夠好,它可以擁有清華、北大優秀本科畢業生同等的認知能力。但即使擁有了這種認知能力,就能確保大數據在企業中可以做好很多工作?答案是否定的。實際上,現實生活中很多優秀的本科畢業生在企業裏發揮的作用並不理想,這是我們需要特別思考的。

值得注意的是,並不是模型的參數決定了它是否能在工作中有效轉化成生産力。有一些任務,即使用很小參數的模型也能解決,還有很多的問題,即使發展到GPT7.0階段也未必能解決。GPT3.5、GPT4.0的參數一直在上升,其主要目的在於自身迭代,要持續更新自身的核心能力。
五、國內的大模型不能用嗎?
在同清華大學電腦係教授、智譜AI首席科學家唐傑老師聊天的時候,我提出了一個問題,智譜AI需要在哪方面著重加強,才能追趕上OpenAI?唐傑老師的回答是加強推理能力。推理能力是什麼?其實,人類所有的智慧工作都可以稱之為推理能力。當不知道一個模型好壞的時候,我建議大家可以向大模型提出一個問題進行檢測,“美國的哪一個州跟其他的州不接壤”,這個問題的正確答案是阿拉斯加和夏威夷,它需要大數據知道美國的地理情況以及州和州之間的關係,但是很多模型的答案都是答非所問。這方面,國外LLaMA2等幾個開源模型做得還比較好。

難道國內的大模型無法使用?我的答案是可以使用。比如人們向大模型提出問題,“湖南和湖北這兩個省會,哪個人口更多一些”,國內的大模型往往會卡住,因為它根本沒有理解這句話的意思,但如果通過操作把它的CoT能力調出來,大模型就有能力將答案推理出來。這如同一名新員工剛剛入職一樣,只要公司給它的任務拆得足夠細,他就能幹好,甚至完成的情況不比清華、北大的畢業生差。我深切地感到,大模型的學習、發展和應用的過程,同人類從小的學習發展過程非常相像,兩者是完全可以類比的。我們講大模型的迭代能力,就是要提高它的推理能力,而推理的過程需要資訊。今天人們想將大模型應用到公司之中,但是大模型並不知道公司原有的生産資料和資訊系統。人們花費大量資金,要解決的問題是什麼?是它想不斷地學習知識,從而提高自己的推理能力,它的最終形態是模型,而不是資訊。它在企業中的價值是提供一個好的模型,所需要的是人們將資訊找過來。
六、大模型在企業落地的好工具:Agent&Copilot
理性和感性的區別是什麼?從哲學講,最大的區別是理性是有目標的,而企業最核心的就是要有目標。正是因為企業是有目標的,企業中絕大多數的生産活動也都是理性的活動,而所有的理性決策、理性活動都需要有對應的理性決策模型和資訊。現在,參數在不斷提高的過程中並沒有增加資訊,不斷提高的參數只是讓模型的推理能力變強大了。做個類比,模型是f,資訊是x,只有把正確的x給到強大的f模型,才有可能算出正確的y,才有可能輔助企業的理性決策和下一步行動,這是企業大模型不好用的核心原因。

除了大模型,當然還有更高級的用法,比如Agent。Agent的本質就是模型和資訊,好的Agent可以把語言模型跟Memory、Tools、Planning的能力有機地組織起來。所以,Agent是今天做大模型創業或者企業去落地大模型使用的非常有效的一種手段。OpenAI也好,國內的大模型也好,它們都如同優秀的大學畢業生,雖然它們都是文科生,但勝在足夠聰明,閱讀理解能力非常強。Agent本質上就是通過大模型的Planning能力,把大模型本身的語言能力、推理能力跟外部的資訊系統和知識全部連接到一起的綜合性系統。對於擁有大模型的企業而言,將公司資訊跟語言模型有機結合起來,相對便捷的方法就是使用Agent。幾個月前,OpenAI發佈了GPTS,它是一個用來生成Agent的工具,其核心就是連接了一些常用的資訊或者知識,把這些資訊和知識給到OpenAI的標準介面,OpenAI就可以基於這些知識去解決一些問題。在企業中,真正想把資訊系統整理好,並且能夠跟大模型連接起來,需要解決諸多難題。最簡單的方法就是使用Copilot。

Copilot是什麼?它跟Agent有何關係?pilot的意思是駕駛員,Co-pilot的意思是聯合駕駛或者副駕駛,即開車時旁邊坐著的那個人。人們最理想的狀態是讓汽車變成無人駕駛,但成本和代價很大。在Copilot中,主駕駛還是人,副駕駛的職能是協助人做一些決策和操作,甚至完成主駕託管的任務,但最後的決定權仍在人類手中。小明助理存在的意義就在於此。
七、哪些行業可以使用大模型?首先是服務業
哪些行業可以使用大模型?哪些工種可以使用大模型?這也是一個很重要的問題。任何行業要想真正用好大模型,真正地創造生産力,都需要把大模型本身産生決策的能力跟最終的行動有機聯合起來,如果兩者無法連結,是無法産生生産力的。人們稱呼人工智慧為下一次工業革命,到底是誰革誰的命,這是一個很重要的問題。蒸汽機和電機的發明,讓工廠革掉了手工作坊的命。我自己有一個觀點,首先開始的將會是服務業革命。比如我們從事的是軟體和分析諮詢的專業服務領域,而GPT的出現帶來了大量複製的可能性,它可以讓人們的腦力勞動被機器自動化或者半自動化地生産出來,像軟體公司、市場研究公司甚至律師事務所等專業服務機構會出現一些兼併、收購、整合甚至革命的情況。在人工智慧發展的今天,製造行業、廣告行業都可能面臨重構,人工智慧會讓過程更加高效,並且打破中間環節的很多瓶頸。但這並不意味著人工智慧會造成大規模的失業,能力提升後,需求也將隨之增加,大家還是有工作可以做的。
八、大模型落地企業的核心是知識工程
企業迎接大模型時代的第一個命題,就是要解決公司的知識工程問題。同時,人們也要思考每個人自己的知識工程是什麼。現代認知心理學將知識分為兩類,一類叫陳述性知識,一類叫程式性知識。編程知識屬於程式性知識。例如,大像是一種動物,這是陳述性知識。把大象放到冰箱裏面分幾步,這是程式性知識。Prompt(提示工程)和CoT(思維鏈)技術是大模型革命性能力發現的重要組成部分,其意義可以媲美人類文字和印刷術的發明。CoT的重點是把程式寫清楚。在小明助理中,只要簡要地表明你的目標,它就可以將Prompt模板寫出來,非常方便。管理大師野中鬱次郎的《創造知識的企業》一書中提出,每個企業中有暗默的知識,也有顯性的知識,企業最核心的就是要把這些知識管理好。在大模型時代,這些知識不僅存在於每名員工的大腦中,存在企業的文檔庫中,甚至存在於每次會議的錄音之中。甚至有一天,大語言模型可以直接執行錄音裏面的知識。這就如同一個非常聰明的清華、北大畢業生在你身邊當助手,你需要做的就是每天拿資料同它交互,就可以高效地提升效率。未來,企業的知識管理邏輯也將發生巨大的變化。Prompt和CoT的出現,實現了大模型和大模型之間互相學習的設想,只要讀懂了你的指令,大模型就可以將這些指令執行得非常好,並且下一個人可以立足訓練成熟的AI繼續發展。每個人都站在巨人的肩膀之上,未來的人工智慧發展速度會非常快。今天大語言模型出現後,很多AI擁有了通用能力,這種通用能力可以賦能各行各業,為每一個人服務。OpenAI是為全世界服務的,中國基礎模型公司做出的産品也是為所有用戶服務的,每一個做垂直應用的企業,每一個企業裏面想用大模型的員工,都可以將模型拿過來直接使用,這是一項非常偉大的變革。
九、知識與數據的安全考量
企業在整理數據和知識的時候,不僅要考慮如何規劃數據、知識,同時也要考慮許可權問題,如果企業將所有許可權全部交給OpenAI,容易引發商業機密洩露。
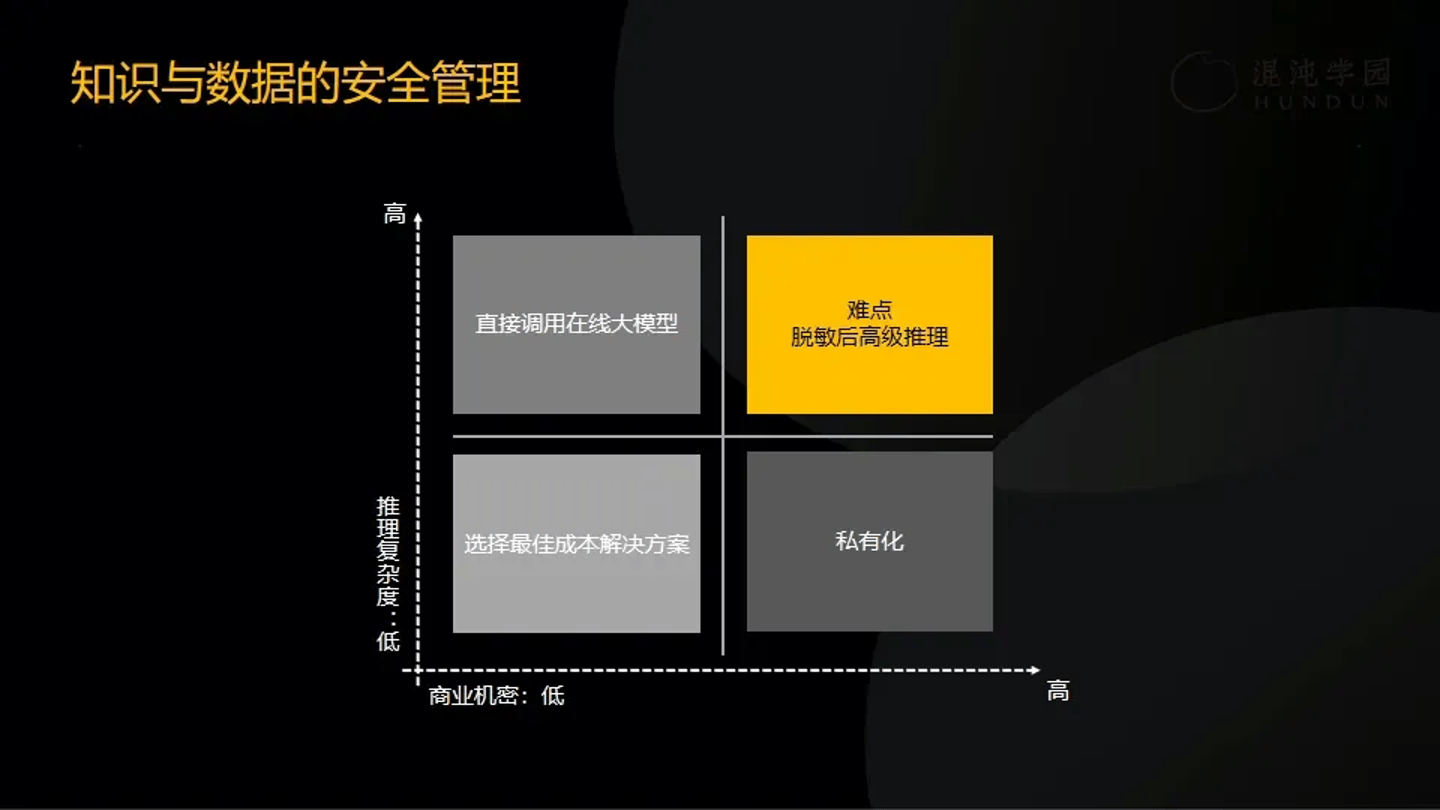
我的建議是選擇兩個維度四象限的邏輯進行分析,包括數據的公開程度、執行任務的推理複雜性等。對於一些低密集又需要高難度推理能力的,可以直接使用線上大模型;對於一些高密集且推理能力不高的,例如財務資訊、HR資訊、研發産品資訊等,可以部署一個私有化模型。企業要做的,就是把對應的密集問題想明白、分好級。