
在人工智慧領域,大語言模型的飛速發展正引領著技術創新的浪潮。近日,人工智慧及大數據科技企業合合資訊發佈了其自主研發的文本向量化模型acge_text_embedding(簡稱“acge模型”),並在權威的中文語義向量評測基準C-MTEB(中文大規模文本嵌入基準)上取得了首名的優異成績。
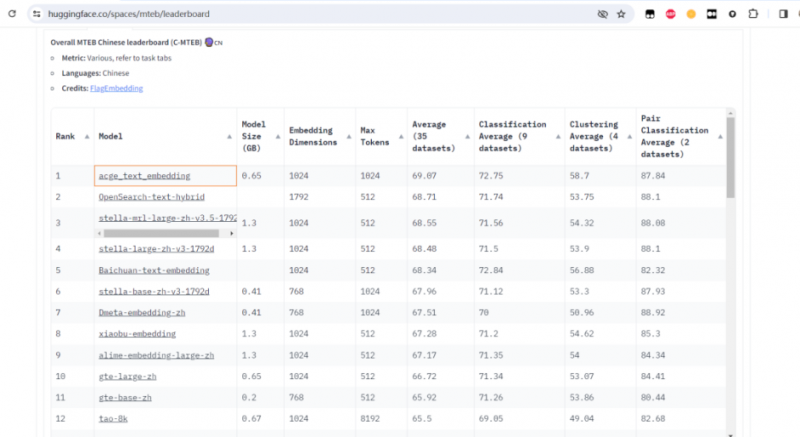
C-MTEB作為業內公認的中文語義向量評測基準,涵蓋了分類、聚類、檢索、排序、文本相似度、STS等六大經典任務,共包含35個數據集,為評估中文語義向量的全面性和可靠性提供了可靠的實驗平臺。合合資訊的acge模型能夠在如此全面的評測中脫穎而出,充分證明了其卓越的性能和廣泛的應用潛力。
Embedding模型作為大語言模型應用落地的關鍵支撐,通過理解查詢的深層含義和上下文,能夠顯著提高搜索和問答的品質、效率和準確性。在網際網路資訊爆炸的時代,Embedding模型的重要性不言而喻。據合合資訊技術團隊成員介紹,相比于傳統的預訓練或微調垂直領域模型,acge模型支援在不同場景下構建通用分類模型、提升長文檔資訊抽取精度,且應用成本相對較低,可幫助大模型在多個行業中快速創造價值,推動科技創新和産業升級,為構建新質生産力提供強有力的技術支援。
具體實踐上,為做好不同任務的針對性學習,團隊使用策略學習訓練方式,顯著提升了檢索、聚類、排序等任務上的性能;引入持續學習訓練方式,克服了神經網路存在災難性遺忘的問題,使模型訓練迭代能夠達到相對優秀的收斂空間;運用MRL技術,實現一次訓練,獲取不同維度的表徵。
值得一提的是,acge模型在體積和性能上均表現出色。相比于目前C-MTEB榜單上排名前五的開源模型,acge模型較小,佔用資源少,輸入文本長度達到1024,滿足了絕大部分場景的需求。此外,acge模型還支援可變輸出維度,企業可以根據具體場景去合理分配資源,實現更高效的資源利用。
未來,合合資訊將繼續致力於人工智慧技術的研發和應用,為全球C端用戶和多元行業B端客戶提供更加數字化、智慧化的産品和服務,推動科技創新和産業升級,為構建新質生産力貢獻自己的力量。
(推廣)
來源:東方網 | 撰稿:合合資訊 | 責編:谷晟 審核:張淵
![]() 新聞投稿:184042016@qq.com 新聞熱線:135 8189 2583
新聞投稿:184042016@qq.com 新聞熱線:135 8189 2583
中國網際網路視聽節目服務自律公約 | 網路110報警服務 | 12321垃圾資訊舉報中心 | 友情連結
版權所有 中國網際網路新聞中心 電話: 057187567897 京ICP證 040089號
網路傳播視聽節目許可證號:0105123 京公網安備110108006329號 京網文[2011]0252-085號

