

IDC、智源最新大模型評測 百度文心大模型雙榜奪魁
發佈時間:2024-06-19 08:42:52 | 來源:中國網科學 | 作者: | 責任編輯:科學頻道
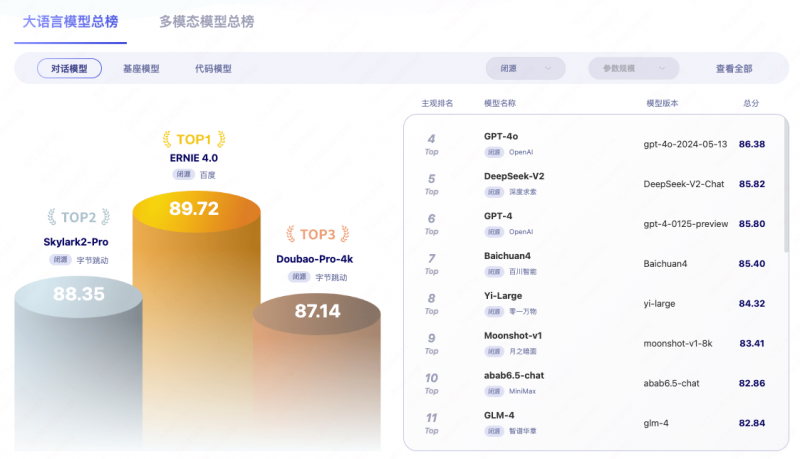
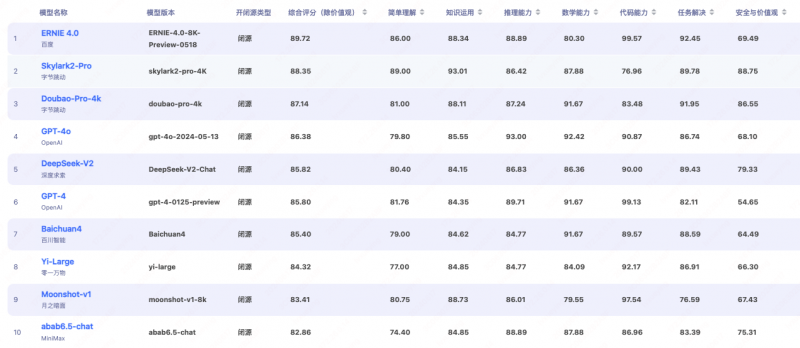
6月17日消息,近日,由北京智源研究院打造的FlagEval天秤大模型評測平臺實現了全面升級,並公佈202406期FlagEval模型評測排行榜單。最新一期榜單顯示,百度文心大模型4.0以89.72的綜合評分在閉源對話模型中排名第一,超過字節雲雀、豆包和阿裏通義千問等一眾國産大模型,以及OpenAI的最新模型GPT-4o。在中文語境下,以文心大模型為代表的國內頭部語言模型的綜合表現已超過國際一流水準的表現。
FlagEval大語言模型評測能力榜單官網截圖
FlagEval天秤大模型評測平臺是智源研究院推出的科學、權威、公正、開放的大模型評測體系,自2023年發佈以來,已從主要面向語言模型擴展到視頻、語音、多模態模型,實現多領域全覆蓋,目前已評測國內外 300余個開源和商業閉源的語言及多模態大模型。資料顯示,FlagEval大語言模型評測體系當前包含6大評測任務,近30個評測數據集,超10萬道評測題目。
FlagEval大語言模型評測能力榜單官網截圖
從榜單中可以看到,百度文心大模型4.0以89.72的綜合評分在閉源對話模型中排名第一,雲雀2-Pro、豆包、GPT-4o分別位居二三四位,百川、零一萬物、kimi等追隨其後。
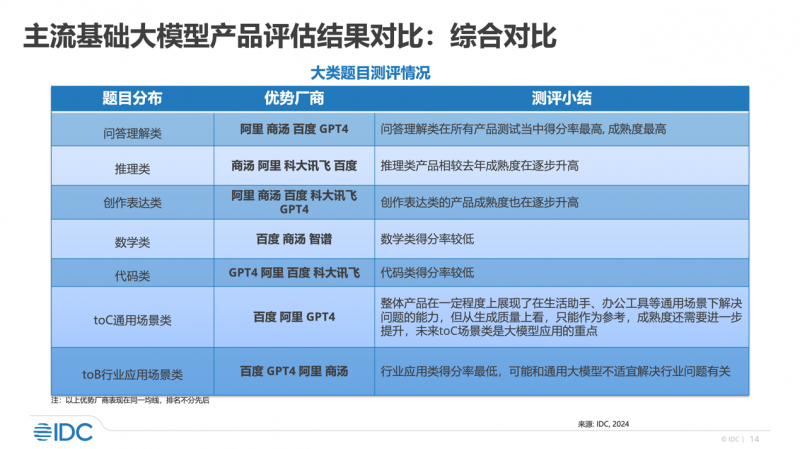
早在上周,國際數據公司IDC發佈的《中國大模型市場主流産品評估,2024》中,百度同樣位於第一梯隊,是唯一一家在7大維度上均為優勢廠商的企業。評測顯示,百度旗下生成式AI産品文心一言和文心一格在問答理解類、推理類、創作表達類、數學類、代碼類的基礎能力,toC通用場景類、toB特定行業類的應用能力等7大維度均具備領先優勢。其他評測廠商中,阿裏獲6項優勢維度,OpenAI GPT-4和商湯分獲5項。
IDC《中國大模型市場主流産品評估,2024》
公開資料顯示,2023年10月,百度文心大模型4.0正式發佈,實現了基礎模型的全面升級,在理解、生成、邏輯和記憶能力上明顯提升。截至目前,文心一言累計用戶規模已達2億,日均調用量也達到了2億。