

星環科技分佈式時序數據庫TimeLyre 9.2發佈
發佈時間:2024-08-02 12:35:45 | 來源:中國日報網 | 作者: | 責任編輯:王琦
在當今數據驅動的世界中,多模態數據已經成為企業的重要資産。隨著數據規模和多樣性的不斷增加,企業不僅需要高效存儲和處理這些數據,更需要從中提取有價值的洞察。工業領域在處理海量設備時序數據的同時,還需要聯動分析警報資訊、設備關係、組織資訊等關係數據或圖數據;金融領域除了常見的行情和訂單流時序數據外,還會採用地理資訊、實時新聞、氣象數據等多種類型的數據輔助決策。然而,要充分挖掘和利用這些多模態數據,傳統單一模型的時序數據庫已顯得力不從心,無法滿足現代多元應用場景中企業對數據使用的複雜需求。
Transwarp TimeLyre是星環科技自主研發的企業級分佈式時序數據庫,具備高吞吐實時寫入、時序精準查詢、超高數據壓縮率等特點,可以支援海量時序數據的存儲、查詢、分析,有效支撐能源、製造、金融領域等多種時序數據業務場景。
近日,TimeLyre正式發佈V9.2版本,支援海量時序數據的同時,具備原生的多模態數據混合存儲能力,能夠整合和處理不同類型的數據,幫助企業實現數據的多維分析。同時提供高性能分析、熱溫冷數據分層存儲、極速時序數據回放分析等新功能,可以有效支撐大規模時序數據湖、投研一體化平臺、時序數據中臺等新場景,充分滿足企業對多模態數據存儲分析的需求,助力企業發揮數據深層價值。
原生多模態架構,支援時序數據與關係數據模型混合存儲
TimeLyreV9.2採用原生多模態架構,來自多種數據源的時序和關係數據經由統一的介面以批量或實時的方式存入統一的存儲引擎中,通過統一的高性能計算引擎Quark進行讀取和分析,支撐上層模型加工、批處理、線上分析、高性能讀取等場景,助力企業更全面、更多維度的數據分析應用。
不同於傳統方案為不同類型的數據單獨部署和使用不同的數據庫産品,TimeLyre以原生的多模態架構高效實現了多種數據模型的轉化流轉與關聯分析,具有複雜度低、開發和運維成本低、數據處理效率高等優勢。

高性能C++計算引擎,向量化計算,顯著提升數據分析性能
依託于星環科技統一的多模型數據管理平臺架構,TimeLyre在計算引擎中納入了高性能C++計算引擎技術,通過使用向量化計算,充分利用了現代CPU的SIMD指令集,借助列式掃描減少了IO開銷。同時採用高性能數據傳輸格式,實現了數據零拷貝,減少了序列化和反序列化的開銷,並借助列式存儲和高壓縮率,減少了網路傳輸的數據量,便於數據更快速地接入高性能C++分析引擎。通過採用高性能分析計算引擎,可以幫助用戶顯著提高數據處理能力和效率,更快獲取分析結果,加速決策過程,降低能耗和硬體成本,幫助用戶在數據驅動的商業環境中保持領先。
熱溫冷數據自動分層存儲,降低存儲成本,優化資源配置
TimeLyre提供全新的熱溫冷數據分層存儲方案,統一接收外部應用的數據寫入和數據查詢,內部按時間或指定條件將熱數據、溫數據和冷數據進行自動轉換。對於熱數據,可以實現毫秒級查詢性能,提供5倍以上數據壓縮率;溫數據支援百毫秒查詢性能,提供15倍以上壓縮率;冷數據提供30倍以上數據壓縮率,滿足數據批量加工需求。熱溫冷數據的分層僅需在建表時通過DDL指定,無需後期運維,即可實現定期後臺自動分層。同時支援指定數據存儲在不同的存儲介質上,進一步降低綜合存儲成本,優化資源配置。
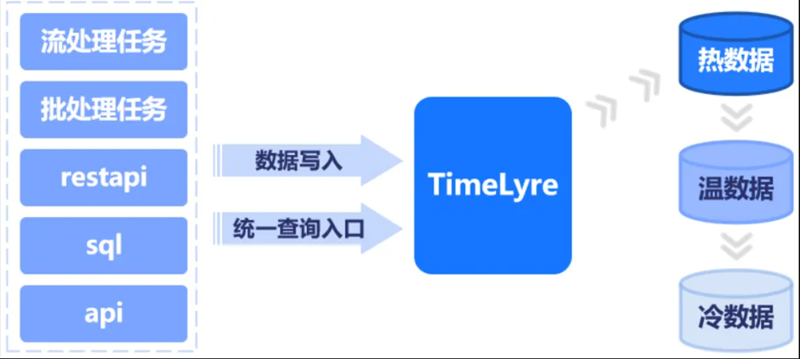
支撐分佈式極速時序回放分析引擎TransMatrix,助力時序數據回放分析
TransMatrix是星環研發的分佈式投研系統,用戶可以將多種數據結構、多種頻率(高、中、低頻)的數據按照時間順序進行回訪;支援原生多模態數據源回放,可以從星環TDH中直接讀取和加工數據源,除了時序和關係數據之外,還支援文本數據、圖數據、圖片數據等,同時允許用戶借助Python開源生態對多模態數據進行加工和分析;內置豐富的時序算子庫,支援自定義算子開發與共用;採用事件驅動的編程範式,提供生成式算子開發介面;提供算子拼接介面與豐富的內置運算式,支援用戶自定義運算式;通過分佈式任務實現多租戶負載均衡、提供分佈式任務配置介面,可實現任務拆分、批量運作、大規模採樣等大型任務。
新場景:大規模時序數據湖引擎,助力企業應對海量時序數據
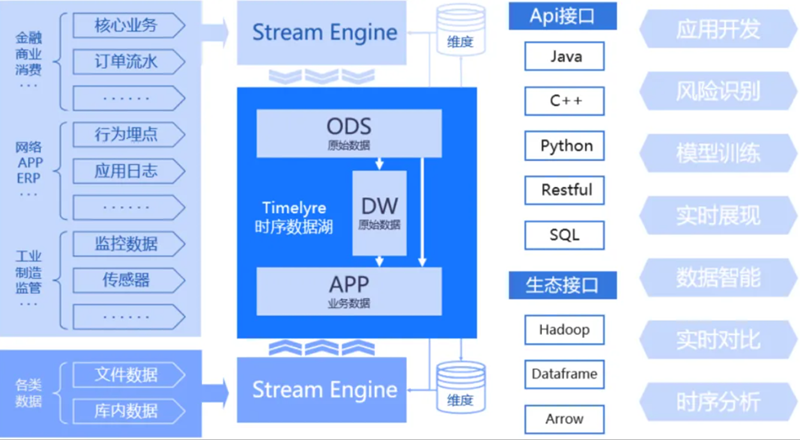
用戶可以基於TimeLyre構建大規模時序數據湖,海量時序數據通過流式引擎進入數據湖內,依託TimeLyre完成ODS層、DW層、維度層數據載入與處理,通過豐富的API介面和開源生態介面支撐上層應用開發、風險識別、模型訓練、實時展示、數據智慧、時序分析等業務場景。以TimeLyre為核心構建時序數據湖,充分利用了産品對海量實時數據的存儲與查詢分析能力,實時寫入性能可達每節點千萬測點,實時查詢性能可達每節點10000QPS。結合流、批計算引擎,滿足業務對端到端秒級時效性的要求。同時支援時序數據與關係數據高效關聯分析、提供完善的SQL支援與靈活可變的Schema定義,為用戶提供全面、高效、靈活的數據管理分析平臺。
新場景:投研一體化平臺技術底座,搭建分佈式投研框架
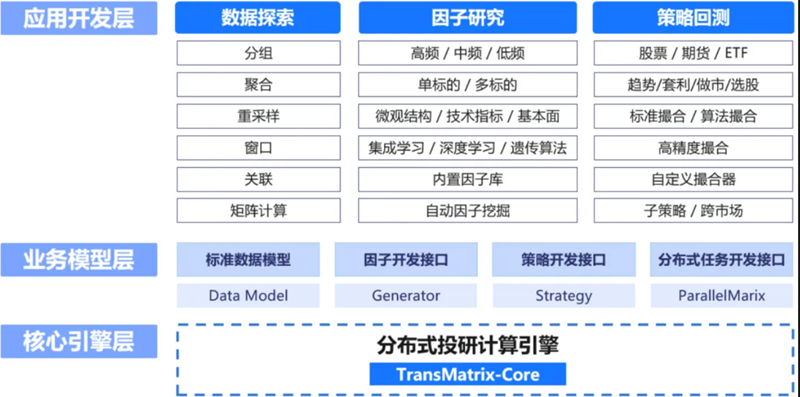
面向金融投研場景,TimeLyre可以作為投研一體化平臺的技術底座,助力企業搭建分佈式投研框架。底層依託時序數據庫TimeLyre及其內置的分佈式投研計算引擎TransMatrix構建投研平臺核心技術底座,通過標準數據介面、因子開發介面、策略開發介面和分佈式任務開發介面對接上層業務模型,助力企業在一體化平臺內實現數據泰索、因子研究、策略回測等應用開發。
新場景:投研數據中臺數據底座,實現多源數據分層管理
依託TimeLyre構建投研數據中臺,參考標準數據分層結構,可將數據分為數據源層、基礎數據層、投研標準層、業務模型層與收益報表層。在數據源層負責從數據廠商、交易所數據、用戶因子數據等外部數據源同步數據,可以做到將原始的行情或因子數據以完全一致的形式同步入投研數據中臺;基礎數據層負責完成數據的校驗、清洗與加工,生成乾淨的基礎投研數據;投研標準層負責將這些數據統一成面向投研過程的標準表模型以及數據結構模型,為用戶遮罩掉不同來源數據在字段名、字段類型等方面的差異;業務模型層負責生成面向特定研究過程的因子與數據;收益報表層負責生成面向投研收益評價的因子與數據,可以將策略的研究結果、投研結果以報表的形式存在時序模型或關係模型中。
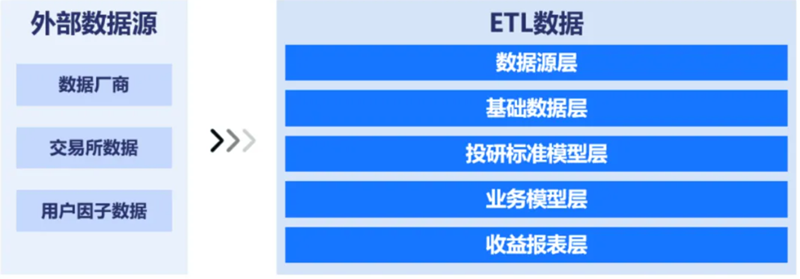
依託TimeLyre構建投研數據中臺可以對接豐富的外部數據源,實現多層次外部數據錄入,支援以投研領域常見的文件形式載入數據、從主流數據庫(MySQL、Oracle等)進行數據同步、通過類似SQL的API接收交易所實時行情、通過Kafka統一接受數據等多種數據接入方式。同時為了應對數據實時和批量更新的需求,提供專業的ETL工具,可以實現數據的一鍵重入,開啟一鍵重入即可自動觸發多層次數據加工,實現投研數據的自動更新,並通過統一的API提供給業務人員進行研究使用。
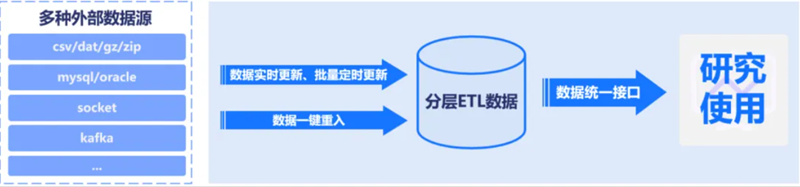
賦能業務:TimeLyre助力某光伏企業打造批流一體時序數據湖方案
某光伏企業為解決數據孤島問題,依託星環科技分佈式時序數據庫TimeLyre構建批流一體的時序數據湖。首先通過數採設備從數據源系統中獲取原始數據,統一經由Kafka消息系統匯入數倉平臺的數據接入區,並通過TimeLyre自帶的流處理引擎Slipstream將數據載入到內部的貼源層,實現時序數據、關係數據等多模態數據的統一存儲。數倉內部通過統一的計算引擎和SQL引擎將數據加工到不同的層次,包括標準表DWD層、中間表MID層、模型表DWS層、維度表DIM層和業務寬表ADS層等,用以支撐上層業務報告、BI報表、數據智慧、實時分析對比、三維展示等應用場景。值得注意的是數倉平臺以TimeLyre為核心,僅通過TimeLyre一個數據庫,就實現了時序數據、關係數據從貼源層到應用層的加工、分析和查詢。
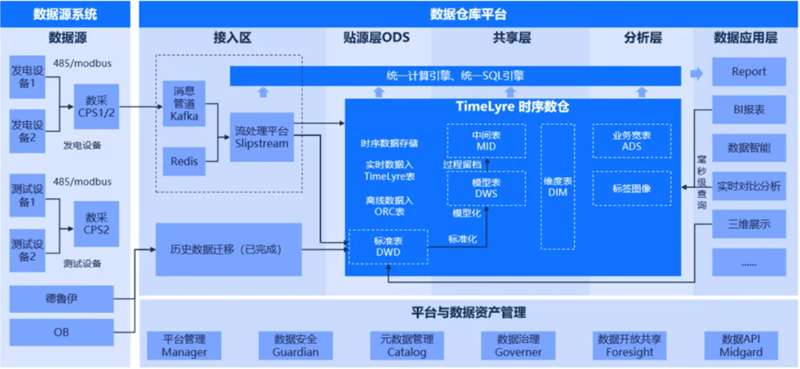
項目基於星環大數據技術實現了光伏數據的統一接入,包括設備測點數據的實時接入以及管理數據、巡檢圖片、運作日誌等數據的全量接入,目前已實現基地3300多臺設備、近30萬測點數據的秒級入庫。並且方案具備水準擴展能力,未來增加硬體資源,也可順利接入新建場站數據。
同時依託星環科技時序數據庫、批處理引擎和分析庫構建的光伏數據底座,可以實現各類數據的存儲和數倉模型加工,通過統一的計算引擎和統一的數據介面,支撐各類可視化數據應用的構建,方便光伏實驗實證分析人員利用大數據技術開展數據對比分析、設備性能查詢、運作曲線查看等日常工作。
此外基於星環一體化平臺與數據資産管理,實現了全平臺數據的統一授權、開發、治理、開放、審計,讓各部門的開發人員,可以快速便利的獲得所需的數據資源,並基於高性能的時序數據湖平臺進行數據分析。