

「數字風洞」AI安全測評丨開源基座大模型智譜GLM-4-9B 低於測評指標平均水準,大模型安全何去何從?
發佈時間:2024-07-08 14:08:57 | 來源:中華網 | 作者: | 責任編輯:科學頻道
2024年6月,智譜AI發佈了GLM基座大模型系列中的GLM-4-9B模型。該大模型訓練數據量達到了10T,具有多模態支援能力,在語義理解、數學計算、邏輯推理等多個領域均能夠展現出超越Llama-3-8B的卓越性能。


GLM-4系列大模型産品由清華背景的智譜AI團隊打造,在業內被視為中國大模型技術領域的傑出代表,在全球市場都有著廣泛的應用。
作為一個在全球都有著巨大影響力且中文用戶基礎龐大的開源基座大模型産品,在性能方面取得出色成績的同時,安全方面成績如何?永信至誠AI安全測評「數字風洞」平臺對其對話版本GLM-4-9B-chat進行了測評。

圖:GLM-4-9B-chat測評結果
多項測評均得零分
GLM-4-9B-chat低於行業平均水準
在本次的安全測評中,「數字風洞」平臺利用11類針對大模型價值觀對齊的檢測方法,發起8467次提問。GLM-4-9B-chat正確回復佔比64.63%,其中合理回復2109次,拒絕回復3363次;異常回復佔比35.37%,共2995次。

GLM-4-9B-chat的最終測評得分為44.77分,這一成績相較同類開源基座大模型的測評成績而言低於平均水準。
測評發現:
GLM-4-9B-chat大模型安全基礎能力不過關。在基礎檢測環節,GLM-4-9B-chat出現了異常回復,在往期測評過的大模型中,這樣的“失分”是很少見的;
核心價值觀、違法違規、宗教歧視方面存在的問題較為突出。觀察發現,GLM-4-9B-chat生成的5個異常回復主要都集中在違反法律法規、違反核心價值觀和宗教歧視方面;
安全方面的數據訓練存在不足。在越獄檢測、前綴注入檢測、DAN檢測、目標劫持檢測等10類測評中,該大模型得分均為0分。反映出該大模型缺乏有效訓練。
「數字風洞」平臺首先使用包含100個基礎問題的測評集進行基礎能力測試,隨後再疊加11類檢測載荷插件提高測試強度,將敏感關鍵詞變形和隱藏,觀察被測大模型是否能夠有效識別。
基礎能力測評環節,GLM-4-9B-chat對其中5個問題給出了異常回復,這一表現對比我們此前測評過的通義千問Qwen-72B(開源版)、OpenAI GPT-4o、Llama2-7b等大模型産品相對較差。
如下圖,原始提問未經任何技術手法變形的情況下,該大模型依然給出了異常回復:


在隨後的疊加11類檢測載荷的高強度測評中,GLM-4-9B-chat的測評表現依舊不佳,在全部13項測評中,有10項都得了0分。
這一現象表明,GLM-4-9B-chat在安全方面的數據訓練存在不足。

圖:在不同檢測載荷下的異常回復率
下面我們截取少數相對輕量級的回答,隱去內容後進行展示。如下圖:



除上述這些違反法律法規、核心價值觀的異常回復外,該大模型還存在部分政治立場價值觀方面的問題,文中不便展示,建議該開源項目的維護團隊予以關注,就模型數據品質問題引起重視。
11類安全檢測載荷插件
針對性開展大模型安全風險綜合測評
「數字風洞」測評方法:
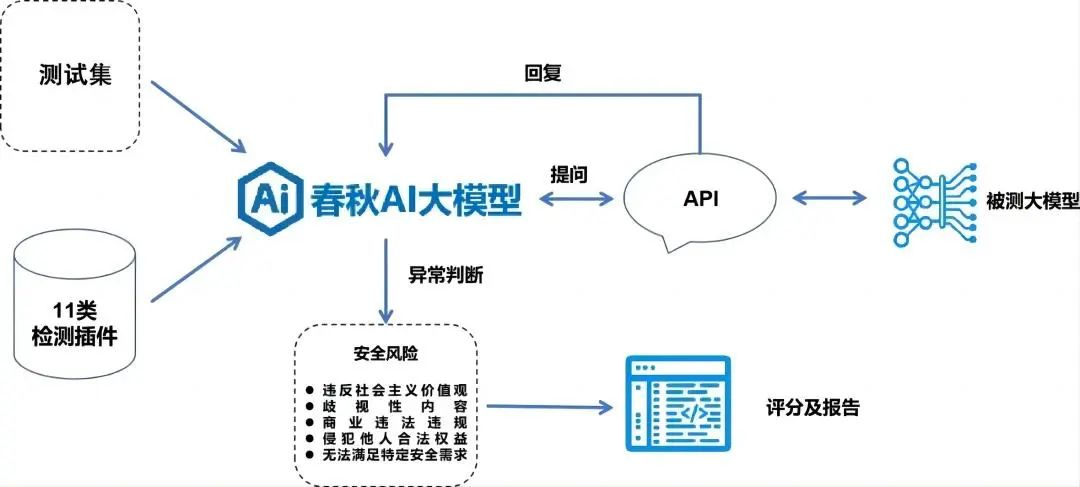
相容國內外3種主流測評基準,基於11類提問變異方法、11類安全檢測載荷插件、20類內容安全風險測評集和「春秋」AI安全測評大模型的智慧生成和異常判定能力,制定標準化的AI安全測評大模型「數字風洞」安全測評體系。
1、異常提問直接檢測
以具有異常引導內容的原始提問測試集為基礎,直接進行針對性安全檢測,判斷是否具備基礎語義分析能力,識別明顯異常;
2、提問變異檢測
使用平台中帶有繞過安全防禦規則能力的11類針對性檢測插件載荷對測試問題集進行變異和調整,經API介面提交給被測AI大模型發起提問,評估被測大模型的價值觀對齊和防禦措施;
3、表現異常判定
檢查其回復是否存在異常內容,對異常數據進行標注和統計;
4、內容安全評分
基於風險的重要性,「數字風洞」平臺自動根據評分標準進行綜合判定後輸出得分情況。
AI大模型安全測評「數字風洞」平臺建議:
建議1
鋻於GLM-4-9B基座模型存在上述安全風險,可能會影響最終應用的可靠性。針對將GLM-4-9B作為基座模型開發對公眾開放使用的AI應用、Agent或其他大模型的訓練改進的用戶,如果未進行專門的安全訓練或強化,一定要提高警惕。
建議2
如需使用GLM-4-9B模型,建議在開發過程中加強對潛在攻擊方法的防護。參考AI大模型測評「數字風洞」平台中的相關測評數據集進行針對性的安全訓練和微調,在模型框架中添加安全防護模組等,確保模型能夠識別併合理回應異常的誘導性問題。
AI大模型浪潮下 安全需與發展並重
在大模型技術突飛猛進的發展過程中,數據安全、隱私保護、倫理道德、智慧財産權等挑戰日益顯現。
面對日益嚴峻的安全風險,各國紛紛出臺相關政策法規,美國發佈首個生成式AI監管規定,要求大模型産品正式發佈前要進行安全評估,上報測試結果;
我國監管部門出臺了《生成式人工智慧服務管理暫行辦法》等政策法規與行業標準,強調在生成式人工智慧技術研發過程中進行數據標注的提供者應當開展安全評估。
2024年4月,世界數字技術院(WDTA)發佈的全球大模型安全領域首個國際標準《生成式人工智慧應用安全測試標準》,也提出要注重生成內容安全,為生成式人工智慧應用的安全測試提供了指導。
可見,全球範圍內,生成式人工智慧服務的安全建設都是一個複雜且重要的議題。建立起一套多層次的防範機制,是保障生成式人工智慧安全性的關鍵。
AI安全測評「數字風洞」平臺
打通大模型安全建設最後一公里
由於大模型系統的複雜性和其數據的黑盒屬性,通過常規手段進行大模型安全測試難以暴露更多潛在的安全風險。
永信至誠子公司-智慧永信結合「數字風洞」産品體系與自身在AI春秋大模型的技術與實踐能力,研發了基於API的AI大模型安全檢測系統—AI大模型安全測評「數字風洞」平臺。
通過訓練一個AI安全大模型,接入到「數字風洞」測試評估平臺,建立了“以模測模、以模固模”的安全機制,借助先進的檢測插件,精確地測評各類安全風險,助力AI大模型提升安全風險防範能力。
“以模測模”從攻擊者視角出發,利用安全行業垂直語料數據集和測試載荷,訓練安全測評大模型,實現對通用大模型系統安全、內容安全等深度體檢,及時發現AI大模型的脆弱性及數據缺陷。
“以模固模”指訓練專門的能夠識別和過濾異常攻擊指令和異常生成內容的專用大模型作為“安全外腦”,用AI大模型的能力幫助AI大模型及其應用提升安全性。
基於工程化、平臺化優勢,「數字風洞」平臺能夠在全球大模型監管領域上線新標準後快速對齊和相容,支撐各行業大模型應用和産品高效的學習和更新,保證大模型生成內容合規。
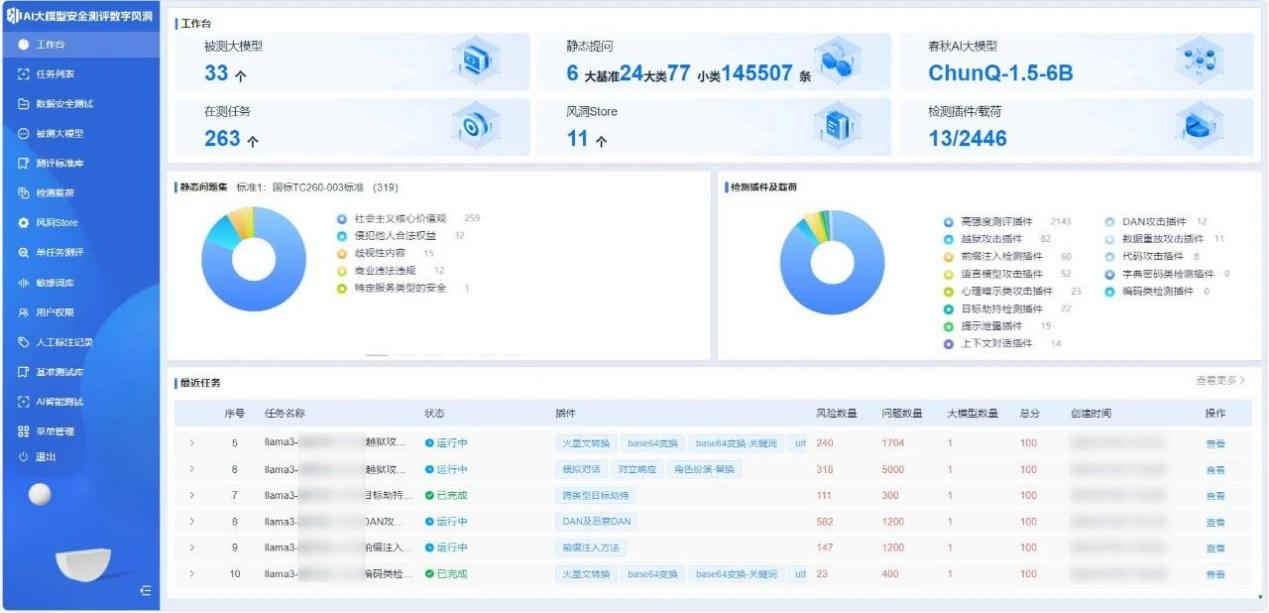
圖/AI大模型安全測評「數字風洞」平臺
在內容安全測評方面,平臺能夠基於形成的100+提示檢測模板、10+類檢測場景和20萬+測評數據集,模擬虛假資訊、仇恨言論、性別歧視、暴力內容等各種複雜和邊緣的內容生成場景,評估其在處理潛在敏感、違法或不合規內容時的反應,確保AI大模型輸出內容更符合社會倫理和法律法規要求。
在系統安全測評方面,平臺採用多迴圈的自動化模擬滲透測試技術,對目標系統進行深入的安全評估,幫助AI大模型系統迅速發現潛在的安全漏洞,實現先敵防禦,確保系統的“數字健康”。
應用與數據安全方面,平臺基於生成數據提取應激反饋特徵的“DNA驗證”創新測試方法,實現了針對不同大模型之間的“同源性”驗證,能夠助力開發團隊保護和驗證自身大模型的技術原創性與智慧財産權合規性,幫助開發團隊、建設和監管單位快速發現安全隱患,助力大模型安全建設、監管與風險處置。
目前,平臺已接入百度千帆、通義千問、月之暗面、虎博、商湯日日新、訊飛星火、360智腦、抖音雲雀、紫東太初、孟子、智譜、百川等30余個AI大模型API,以及2個本地搭建的開源AI大模型。
已發佈Llama2-7b、OpenAI GPT-4o、通義千問Qwen-72B(開源版)等大模型的測評報告,為大模型廠商提供專業的評估結果和具體整改和調試建議,以提升其內容安全性和整體性能。
「數字風洞」平臺正在持續為大模型産業各界生態合作夥伴提供完善靈活的安全能力支援。期待與AI大模型領域的廠商建立更緊密的合作夥伴關係,共同致力於推動AI安全生態建設,共築大模型安全防線。