

北京中考試卷出爐,來看九章大模型對決GPT-4o
發佈時間:2024-07-01 13:07:49 | 來源:新浪科技 | 作者: | 責任編輯:科學頻道
繼高考之後,各地中考也陸續落下帷幕。之前,多家機構和媒體用高考題評測大模型們的“高考成績”,吸引了不少眼球。那面對中考題,尤其是大模型不太擅長的數學科目,又會有怎樣的結果呢?
讓我們以今年北京中考數學試卷為例,再測一下大模型們的答題實力吧!
今天的測試“選手”分別是國産九章大模型和GPT-4o大模型。九章大模型(MathGPT),是學而思自主研發,面向全球數學愛好者和科研機構,以解題和講題演算法為核心的大模型。此前在Matheval排行榜多個維度的評測中都排名第一。GPT-4o是由OpenAI公司研發,是國際上備受關注的大語言模型之一,除了自然語言處理,GPT-4o還具備一定的推理能力,能夠處理需要邏輯分析和判斷的問題。
究竟誰在這場“數學比拼”中更勝一籌,讓我們一起看看。
一、先説結論
本次測試選擇了2024年北京中考數學試卷中的17道題,分別是8道選擇題、8道填空題以及1道解答題。
在測試題目的比拼中,九章大模型的正確率為85%,GPT-4o的正確率為75%。
【九章大模型(MathGPT)】
選擇題8題,做對5題。
填空題8題,做對6題。
九章大模型總分 = 5 * 2分 + 6* 2分+1分 = 23分 (滿分30分)
【GPT-4o】
選擇題8題,正確5題。
填空題8題,正確5題。
GPT-4o總分 = 5* 2分 + 5* 2分 = 20分 (滿分30分)
注:填空題的最後一題有兩問共2分,答對一問記1分。
在這次AI比拼中,九章大模型憑藉其在數學領域的專業優勢,取得了較高的正確率。這表明在特定領域,尤其是數學解題,定制化的大模型能夠展現出更強的性能。然而,兩者在複雜圖題上的表現都存在不足,説明在這類問題的邏輯推理和步驟展示上,AI仍有待提升。
從教育的角度看,AI大模型為學習者提供了及時反饋和考點解析,有助於增強學習體驗和深度理解。但同時,AI的局限性也提醒我們,它目前還不能完全替代人類教師的角色,尤其是在精細化指導和情感交流層面。
未來,AI與教育的結合可能會推動教學模式的創新,如人機協同教學以及自適應學習路徑等。要實現這些願景,AI技術需要在保證準確性和普適性的同時,進一步增強其在複雜情境下的理解和應用能力。
二、測試方法
1、測試題目:2024年北京中考數學試卷選擇題的第1-8題,填空題的第9-16題,解答題第26題。
2、由於數學解答題的評估涉及複雜的推理步驟和邏輯判斷,直接評判模型答案的正確性較為困難。因此,本次測試的重點放在了選擇題和填空題上,這些題目通常有明確的正確答案,便於公正地評估模型的解答能力。
三、選擇題,難分伯仲
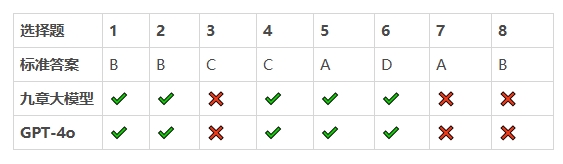
以一道經典的概率推論題為例,一起來看一下二者的分析過程
九章大模型如下作答:

GPT-4o分析思路:

四、填空題,九章大模型獲勝
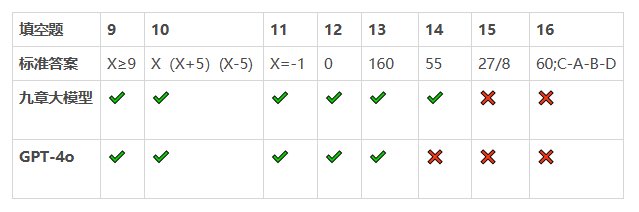
第14題,GPT-4o回答錯誤
九章大模型正確解答:

GPT-4o的分析過程:

第16題,均出現錯誤
九章大模型只答對了第一問,其分析過程:

GPT-4o兩問均回答錯誤,其解答過程:
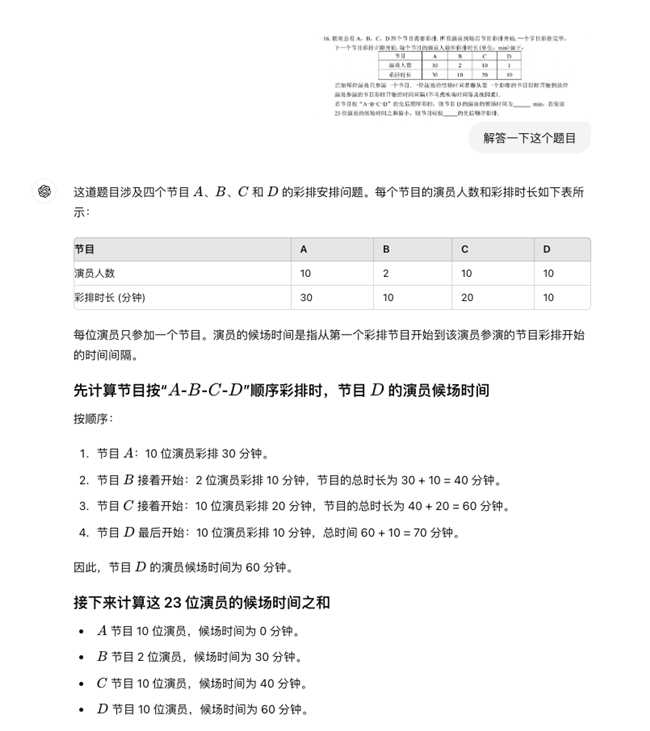

五、解答題
第26題,九章大模型最終答案正確。
九章大模型的分析過程:

GPT-4o最終答案有誤,其分析過程:
