

Yandex推出開源大語言模型訓練工具 可節省高達20%的圖形處理器資源
發佈時間:2024-06-17 13:44:56 | 來源:中國網科學 | 作者: | 責任編輯:科學頻道
· Yandex推出YaFSDP,這是一種更快、更高效的大語言模型(LLM)訓練方法。
· YaFSDP最高加速達到26%。這種針對圖形處理器(GPU)消耗的優化使開發人員和企業每月可節省數十萬美元。
· YaFSDP是目前改善圖形處理器通信和減少記憶體使用的最有效方法。
· YaFSDP方法可以在Github上免費獲取。全球的機器學習(ML)工程師和企業可以使用它來提高大語言模型訓練效率。
全球科技公司Yandex最近推出了YaFSDP,這是一種用於訓練大型語言模型(LLM)的開源方法。
YaFSDP是目前在大型語言模型訓練中增強圖形處理器(GPU)通信並減少記憶體使用量的公開可用的最有效工具,與FSDP相比,根據架構和參數數量,其速度最多可提高26%。通過使用YaFSDP縮短大型語言模型的訓練時間,可以節省高達20%的圖形處理器資源。

Yandex公司高級開發人員、YaFSDP開發團隊成員米哈伊爾·赫魯曉夫(Mikhail Khruschev)表示:“目前,我們正在積極試驗各種模型架構和參數大小,以擴展YaFSDP的多功能性。我們很高興能與全球機器學習社區分享我們在大型語言模型方面的成果,為提高全球研究人員和開發人員的可訪問性和效率做出貢獻。”
YaFSDP案例
大型語言模型訓練是一個耗時且資源密集的過程。在大型語言模型訓練期間,開發人員必須有效管理三種主要資源:計算能力、處理器記憶體和處理器通信。自行開發大型語言模型的機器學習工程師和企業會投入大量時間和圖形處理器資源來訓練這些模型。模型越大,與其訓練相關的時間和費用就越多。
需要説明的是,大型語言模型訓練依賴於組織成集群的眾多圖形處理器,這些集群是互連的圖形處理器陣列,可以執行訓練具有數十億參數的模型所需的大量計算。在集群內的處理器之間分配計算需要持續的通信,這往往會成為“瓶頸”,減緩訓練過程並導致計算能力的低效利用。
為了克服這一瓶頸,Yandex開發人員創建了YaFSDP,優化了學習速度和性能,通過消除圖形處理器通信效率低下的問題,確保了訓練時僅需要關注必要的處理器記憶體,並使圖形處理器交互不受干擾。這也使全球人工智慧開發人員在訓練模型時能夠使用更少的計算能力和圖形處理器資源。例如,在涉及一個具有700億參數的模型的預訓練場景中,使用YaFSDP可以節省大約150個圖形處理器的資源,這相當於每月節省大約360萬至1080萬元人民幣(取決於虛擬圖形處理器提供商或平臺)。
YaFSDP的訓練效率
YaFSDP是FSDP的增強版本,在大型語言模型訓練中通信最密集的階段,如預培訓、對齊和微調,均優於FSDP方法。YaFSDP在Llama 2和 Llama 3上顯示的最終加速結果表明,其訓練速度有了顯著提高,在 Llama 2 70B和Llama 3 70B上分別達到21%和26%。當與Yandex的其他性能增強解決方案結合使用時,該方法可將某些模型的訓練過程加速高達45%。
“YaFSDP在13至700億個參數的模型上顯示了令人印象深刻的結果,在30至700億個參數範圍內的表現尤為強勁,”米哈伊爾·赫魯曉夫表示,“目前,YaFSDP最適合基於LLaMA架構的廣泛使用的開源模型。”
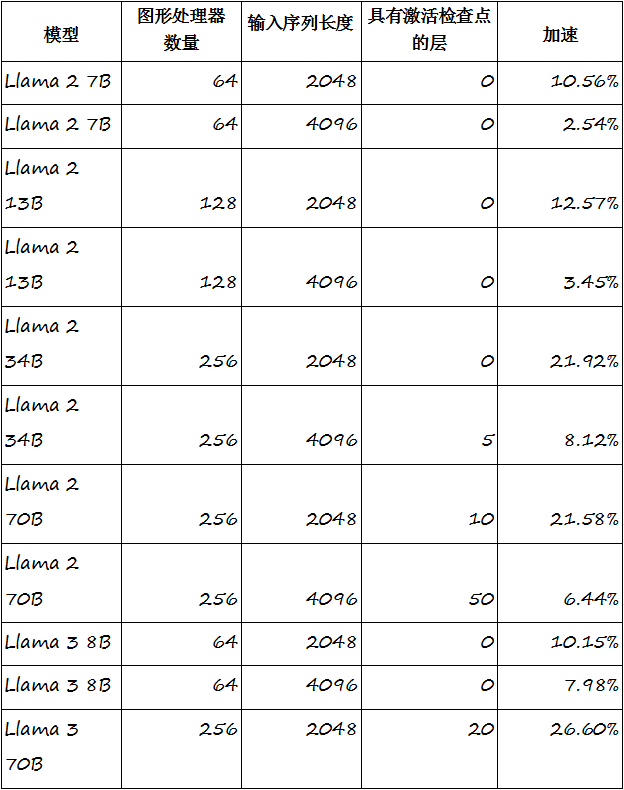
圖: YaFSDP方法可以有效地用於基於轉換器的多層文本生成模型(多層感知器),這些模型大多以類似 LLaMA的模型為代表。在700億參數模型的預訓練場景中,使用YaFSDP可以節省約150個圖形處理器的資源。
YaFSDP並不是Yandex的第一個開源工具。該公司此前曾分享過其他幾款在機器學習社區中備受歡迎的工具,包括:
· CatBoost,一個用於決策樹梯度提升的高性能庫。
· YTsaurus,一個分佈式存儲和處理的大數據平臺。
· AQLM,用於大型語言模型極端壓縮的最先進的量化演算法之一,由Yandex Research、俄羅斯國家研究型高等經濟大學(HSE University)、奧地利科學技術研究所(IST Austria)和NeuralMagic聯合開發。
· Petals,一個旨在簡化大型語言模型訓練和微調過程的庫,由Yandex Research、俄羅斯國家研究型高等經濟大學、華盛頓大學、Hugging Face、ENS巴黎-薩克雷分校和Yandex數據分析學院合作開發。