

網路配圖
近日一則交大教授訓練機器識美女的新聞引發關注。繼11月下旬訓練機器以86%的成功率識別罪犯和非罪犯的照片後,上海交通大學教授武筱林近日又發表了“機器看相”第二季:人工智慧可以成功鑒別“清純”美女和“妖艷”美女,其審美與中國高校男生高度一致。
“是看臉認一個人難,還是判斷一個服務員的笑是出自真誠還是敷衍更難?”,12月17日,在接受採訪時,武筱林拋出了這個問題,來揭示他做的這一系列可能觸及社會倫理敏感點的研究的意義所在。

網路配圖
目前人臉識別系統已能成功鑒別人類的生物性特徵,包括性別、種族、年齡甚至情緒。下一個問題非常吸引人而又充滿挑戰性:人工智慧是否能基於人臉識別推測人類的社會性特徵呢?
武筱林正在進行的這一系列研究,正是為了解答這個問題,或者説,他是在迫使我們直面一個嚴肅的現實:人工智慧已經具有了認同人的情感和性格的潛力。武筱林的上一篇訓練機器進行“罪犯識別”的論文已經召來了褒貶不一的回應郵件,有些人甚至嚴肅地敦促他“撤稿”。他這次在論文的引言部分寫道,“我們不能因為社會禁忌和政治觀念,就在不加以檢驗的情況下否定這種可能性”。
在上一篇論文中,武筱林團隊運用電腦視覺和機器學習技術檢測1856張中國成年男子面部照片,其中將近一半是已經定罪的罪犯。實驗結果顯示,通過機器學習,分類器可以以86%的準確率區分罪犯與非罪犯這兩個群體的照片。特別是在內眼角間距、上唇曲率和鼻唇角角度這三個測度上,罪犯和非罪犯存在較為顯著的差距。平均來講,罪犯的內眼角間距要比普通人短5.6%,上唇曲率大23.4%,鼻唇角角度小19.6%。同時,他們發現罪犯間的面部特徵差異要比非罪犯大。
而最新出爐的這篇論文題為Automated Inference on Sociopsychological Impressions of Attractive Female Faces(《自動推斷有吸引力的女性面孔造成的社會心理學印象》),目前上載在預印本網站arXiv上。
武筱林的研究團隊這次把目光轉向了女性,而且是長相有吸引力的女性。儘管東西方都有“情人眼裏出西施”的説法,但在實際生活中,大眾對陌生女性的審美還是較為一致的。同時人們還會給不同的“美女”貼上不同的標簽,有些是肯定性的標簽,比如“甜美”、“可愛”、 “優雅”、“溫柔”、“體貼”;有些是否定性的標簽,比如“做作”、“虛榮”、“冷漠”、“輕浮”。這些標簽直接從外表指向了女性的一些內在性格甚至品格。
比起犯罪性來,判斷對“美女”的審美給人工智慧提出了更大的挑戰,因為審美在傳統上被認為是一種複雜的個人“口味”,糅合了觀察者和被觀察者的個性和社會價值觀。
研究團隊將兩組照片樣本展示給22名中國男性研究生,發現儘管他們對於照片上貼的標簽高度認同,但他們無法具體解釋他們是如何做出這樣的判斷的。他們幾乎都給出了非常模糊的回答,比如“我就是這麼感覺的”。

網路配圖
“褒義組”照片樣本
那麼,人工智慧否把握這種模糊的“感覺”,由女性長相推斷出她們的內在性格呢?
武筱林團隊首先進行了半自動化的樣本採集。他們在百度圖片上用“單純美女”、“甜美少女”等關鍵詞進行檢索,並把照片分為S+和S-兩組。
S+包含帶有以下標簽的美女照片:清純、柔美、甜美、秀美、單純、大方
S-則包含以下標簽:嬌艷、俗氣、張揚、風騷、輕佻、輕浮、嫵媚

網路配圖
“貶義組”照片樣本
S+和S-分別傾向於褒義和貶義的標簽,且在女性的支配力、可信賴度、單純程度等內在個性上有不同程度的暗示,本文簡單將這兩組稱為“褒義組”和“貶義組”。
然後,所有搜索結果又由中國男性研究生進行了人工排查,去掉一些由於複雜語義造成的錯誤搜索結果,比如有些照片帶有反諷性質的標簽。
研究團隊最後得到了共3954張中國美女照片,其中“褒義組”2000張,“貶義組”1954張。
由於受訪的研究生們無法指出他們做出判斷的細節依據,武筱林團隊採用了深度卷積神經網路(CNN)進行研究。在實驗中,他們用數據集中的80%進行訓練,10%用於驗證,剩餘10%進行測試。
實驗的結果是,經過訓練的機器鑒別“褒義組”和“貶義組”的準確率達到了80%。

機器識別準確率達80%
接著,由於受訪男性研究生普遍認為“貶義組”的照片“不自然”,研究者懷疑影響男性做出審美判斷的重要依據是女性的化粧程度。但這個猜測很快被實驗推翻了。當把所有照片調成灰階圖,重復上面的過程後,CNN分類器的識別準確率只下降了6%。
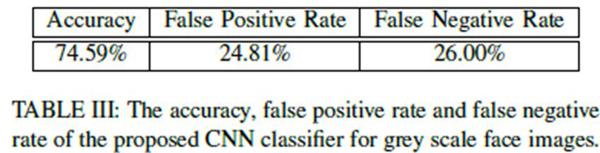
網路配圖
換成灰階圖後的機器識別準確率仍有75%
此外,濃粧還可能造成面部色彩的對比度和飽和度變高。這點得到了數據分析的證實。“褒義組”的色彩對比度比“貶義組”平均低了14%,飽和度平均低了5%。此外,“貶義組”照片在色彩對比度和飽和度上差異性更大。這與中國傳統推崇的“自然美”一致。研究者猜測,這種色彩對比度和飽和度上的差異是機器做出判斷的重要依據之一。
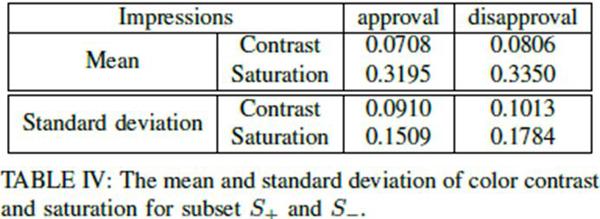
網路配圖
“褒義組”和“貶義組”色彩對比度和飽和度的均值和標準差
最後,武筱林團隊排除了機器過度學習的可能性。他們將數據集隨機打亂後訓練機器,結果機器只能以50%的概率隨機“猜”分類。
文章最後總結道,這篇論文是上一篇論文《基於面部識別的犯罪性推斷》的續集,再次證明了人工智慧不僅可以通過人臉識別鑒別生物性特徵,還可以鑒別社會心理層面的特徵。
在閱讀論文時,發現論文中附帶的“褒義組”照片中出現了演員楊穎。鋻於武筱林的研究採用了百度圖片搜索,樣本中出現一些演藝圈人士和“網紅”的照片不足為奇。但在採訪中,武筱林表示他和他的研究生都對“網紅”群體知之甚少。然而,他們已經對這個群體産生了研究興趣,甚至打算拿她們作樣本,進一步檢驗論文中的演算法。
武筱林説道,他的研究生已經在收集一批女主播的照片,並記錄網友對她們長相的綜合性評價。在收集完成後,他們將把這一批全新的數據交給人工智慧甄別,檢驗電腦的“審美”是否和網友一致。
武筱林打比方説道,之前他們就像訓練電腦成功通過了高考,但現在他們重新找了一批“怪題” 來考驗電腦,看看人工智慧的學習能力到底有多強。
