

成果速遞丨ACM MM 2024:中科視語提出FiLo,實現工業場景零樣本異常檢測新突破
發佈時間:2024-07-30 16:29:18 | 來源:中華網 | 作者: | 責任編輯:科學頻道
在工業生産和品質控制領域,異常檢測始終是一個關鍵問題。傳統的異常檢測方法通常依賴大量的正常樣本進行訓練,但在保護用戶數據隱私或應用於新生産線時,這些方法往往不適用。零樣本異常檢測在這種情況下應運而生,其目的是在沒有目標類別物體訓練數據的情況下,直接進行異常檢測。
近日,中科視語和中國科學院自動化研究所的研究團隊提出了一種新的零樣本異常檢測方法——FiLo。 FiLo方法通過細粒度描述和高品質定位模組,在異常檢測和異常定位兩個方面取得了顯著的性能提升,在零樣本異常檢測工業場景中取得了業內最好性能。

現有的零樣本異常檢測方法通常依賴於多模態預訓練模型的強大泛化能力,通過計算圖像特徵與手工編寫的表示“正常”或“異常”語義的文本特徵之間的相似度來檢測異常,並根據文本特徵和每個圖像塊特徵的相似度來定位異常區域。然而,通用的“異常”描述往往無法精確匹配不同對象類別中的各種異常類型。此外,文本特徵與單個圖像塊的特徵的相似性計算難以準確定位具有不同大小和尺度的異常。
中科視語研究團隊提出的FiLo方法為了解決現有零樣本異常檢測方法在異常檢測和異常定位兩個方面存在的問題,提出了兩個有機結合的模組:自適應學習的細粒度描述模組(FG-Des)和位置增強的高品質定位模組(HQ-Loc):
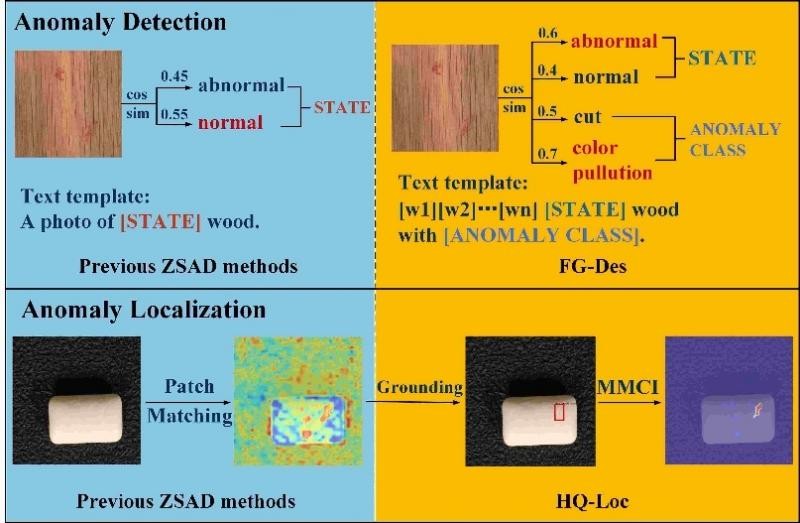
自適應學習的細粒度描述模組(FG-Des)主要利用大語言模型(LLMs)的強大知識來生成每個物體類別可能出現的細粒度異常類型,並採用自適應學習的文本模板替代手工編寫的文本內容,提高了異常檢測的準確性和可解釋性。
位置增強的高品質定位模組(HQ-Loc)利用Grounding DINO進行初步定位,並通過位置增強的文本提示和多尺度、多形狀的跨模態交互模組(MMCI)來準確定位不同大小和形狀的異常。
結合了 FG-Des和 HQ-Loc兩個模組的 FiLo方法的整體結構如下圖所示:
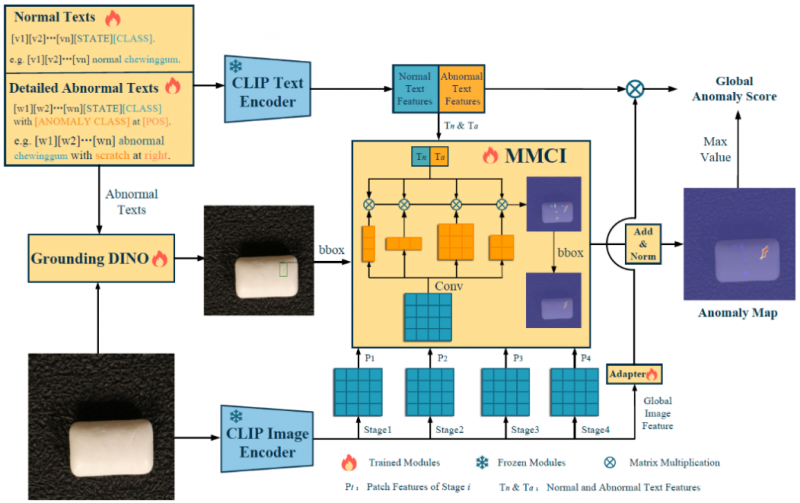
FiLo首先通過大語言模型(LLMs)生成每個類別可能存在的細粒度異常類型列表,然後將細粒度異常描述填入可學習的文本模板中,通過 CLIP文本編碼器後得到表示“正常”和“異常”語義的文本特徵。與此同時,FiLo還將待檢測圖像和大語言模型生成的細粒度異常描述內容輸入到Grounding DINO中,以獲得初步的異常定位框,並將初步定位框的位置資訊也添加到文本特徵中。
接下來,FiLo將待檢測圖像輸入到CLIP圖像編碼器以提取中間層特徵,這些特徵通過多尺度、多形狀的跨模態交互模組(MMCI)與含有位置資訊的文本特徵交互,生成異常分數圖。最後綜合各中間層的異常分數圖,即可得到最終的異常圖和全局異常得分。
通過這種方法,FiLo能夠充分利用LLMs的強大先驗知識和Grounding DINO的初步定位能力,再結合MMCI模組的多尺度、多形狀特徵交互,有效提升了異常檢測的準確性和精確定位的能力。
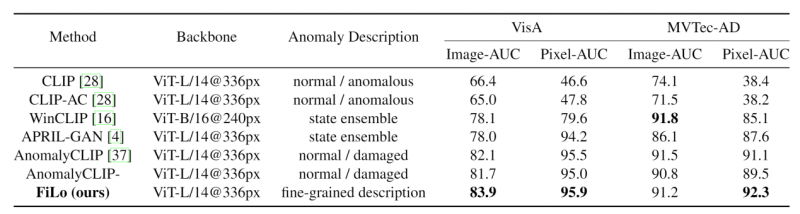
基於上述方法結構,FiLo研究團隊在目前流行的 MVTec-AD和VisA兩個工業異常檢測數據集上進行了實驗,與現有零樣本異常檢測方法相比,FiLo取得了最先進的性能,實驗結果如下表所示:
下圖還展示了FiLo在一些實例上的異常檢測和定位結果,可以發現相比于 CLIP的原始輸出,經過 Grounding DINO的定位框篩選和MMCI的多尺度交互後,FiLo能夠更加準確地定位出異常位置。
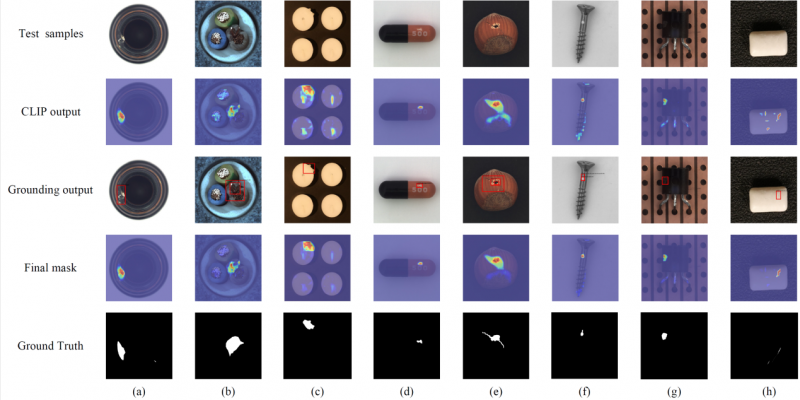
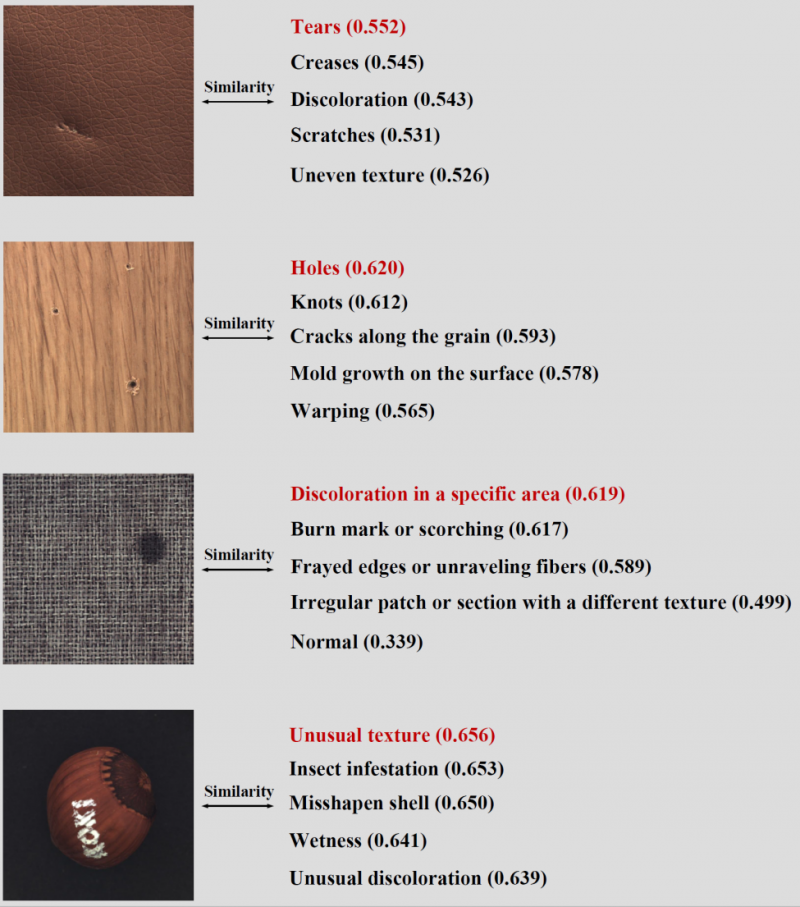
除此之外,通過查看與圖像特徵最相似的細粒度異常描述中的內容,我們還可以知道圖像中存在的具體異常種類,為模型的判斷提供了依據,提高了模型決策的可信度和可解釋性。
FiLo論文已經被人工智慧和多媒體領域頂級會議 ACM MM 2024接收,論文預印版已發佈于 Arxiv上,並開源了相關代碼。
研究團隊認為,現有異常檢測方法往往只注重判斷圖像中是否含有異常,而不重視異常的具體內容,通過借助大語言模型的豐富知識,後續研究可以增強異常檢測方法對具體異常類型的判斷,增加方法的實用性和可信度。
論文地址:[2404.13671] FiLo: Zero-Shot Anomaly Detection by Fine-Grained Description and High-Quality Localization
https://arxiv.org/abs/2404.13671
代碼地址:
https://github.com/CASIA-IVA-Lab/FiLo