

近日,國內領先的人工智慧、大數據和數據安全産品及服務提供商拓爾思資訊技術股份有限公司在京發佈了拓天大模型,並面向媒體、金融、政務領域,推出了三大行業大模型。據悉,拓天大模型是拓爾思基於在NLP領域30年技術創新成果、10餘年高品質數據和知識資産積累,以及在垂直行業10000多家企業級用戶應用實踐而推出的。
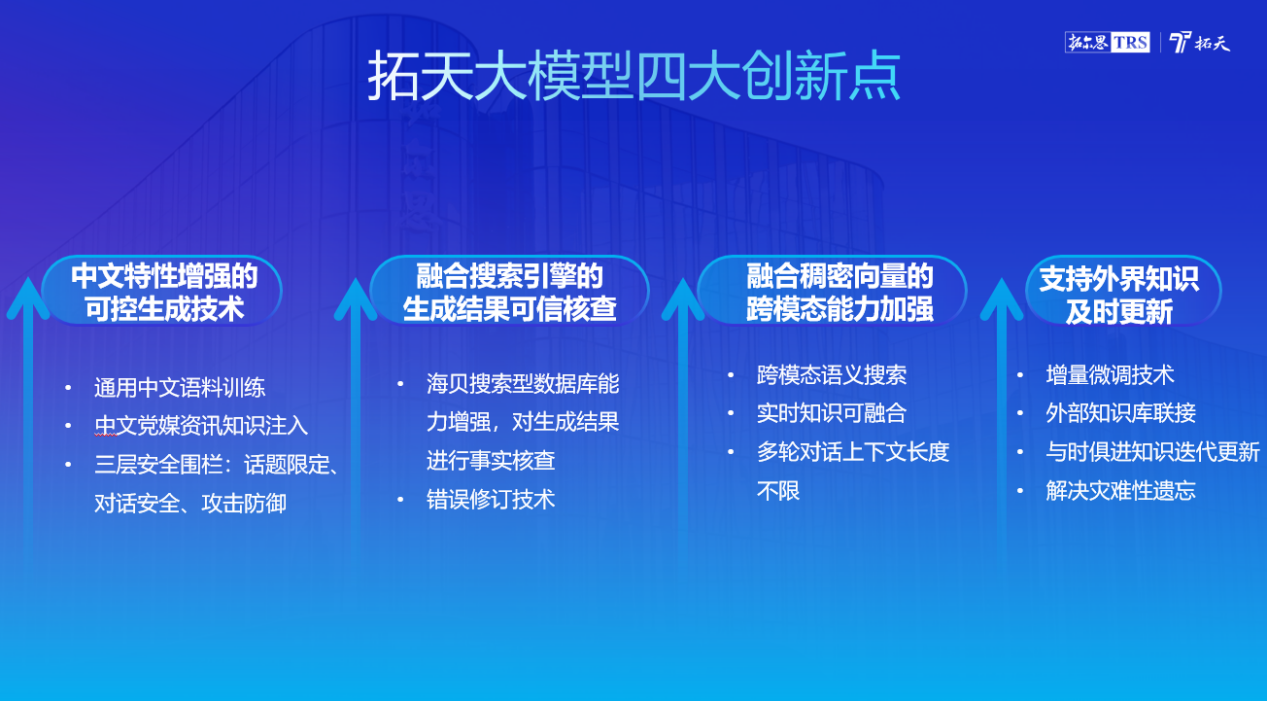
拓天大模型四大創新點
拓天大模型擁有內容生成、多輪對話、語義理解、跨模態交互、知識型搜索、邏輯推理、安全合規、數學計算、編程能力和插件擴展十大基礎能力,具有中文特性增強的可控生成技術、融合搜索引擎的生成結果可信核查、融合稠密向量的跨模態能力加強以及支援外界知識及時更新四大創新點。
大模型的技術突破為人類的技術視野掀開了全新AI宇宙的一角,讓人類可以暢想萬花筒般的未來。拓爾思總裁施水才在之前的成果發佈會上,就從AI科技企業角度闡述了獨到的大模型世界觀。

總裁施水才
施水才表示,大模型的運營基於算力、數據和基礎軟體三大要素,在現實世界中,行業、企業、專業之間存在眾多獨立的數據領地,龐大的數據量和貫通數據領地的難度預示著通用大模型的落地難度。大模型的落地應用會更早、更多地體現在行業、企業等垂類大模型,同樣垂類大模型的數量也會大大超過通用大模型。
通用大模型在專業領域落地存在巨大的挑戰,包括品質、時效、可控、成本等。同時每一個領域都有專業或私域的知識體系,擁有極為龐雜的知識量,僅靠通用大模型無法滿足垂直領域的需求。
和通用大模型相比,拓爾思拓天大模型基於多年自主研發成果,在自主可控、中文特性加強、專業知識加強、實時數據接入、內容安全和價值觀對齊、客戶私有化部署等方面具有領先優勢,並與業務場景深度融合,為用戶帶來生産力變革。
在談到如何不斷迭代“拓天大模型”的品質,以應對市場需求時,施水才表示,拓爾思本身就擁有自研的搜索引擎技術,配合專業領域實時數據,以及自主研發和開源相結合的大模型演算法,通過對媒體、金融、政務等垂直領域數據集進行清洗與處理,進行專業預訓練增強,實現專業能力的提升。
目前,拓爾思擁有千億級“全、準、新”的無監督訓練數據和微調優化知識數據,可針對優勢行業訓練出高品質的行業大模型,為媒體行業內容生産與搜索推薦、金融行業的智慧風控與投研、政府的政策分析與公文輔助寫作等垂直領域提供深度賦能,滿足行業用戶的專業化智慧創新需求。
同時,拓天大模型通過剪枝、量化、稀疏、蒸餾等部署優化方案,可有效降低大模型對算力資源的要求。拓天推出的垂類大模型參數在百億級,當前市場主流推理卡單卡就可以滿足運作要求,實現模型輕量化部署。
對於拓爾思在大模型領域未來發展,施水才認為,語言大模型是大模型的核心,也是多模態大模型的基石。未來,拓爾思將持續建立和強化拓天大模型商業生態,與行業知識專家、平臺型企業、行業頭部企業等展開領域知識、算力、業務創新等方面的合作,持續迭代拓天大模型在更多的行業落地,讓千行百業的用戶真正分享到大模型帶來的商業價值。
