中科視語提出工業異常檢測大模型AnomalyGPT,實現零樣本異常檢測
發佈時間:2024-05-22 09:55:54 | 來源:大眾網 | 作者: | 責任編輯:趙茜工業異常檢測是工業生産中不可或缺的一部分,然而現有的工業異常檢測方法通常只能為測試樣本提供異常分數,需要人工設定閾值以區分正常和異常樣本,這限制了這些方法的實際應用場景。此外,現有的大模型在圖像理解方面展現了卓越的能力,但是缺乏特定領域知識,而且對圖像中局部細節的理解較弱,這導致這些大模型不能直接用於工業異常檢測任務。
近日,中科視語和中國科學院自動化研究所的研究團隊針對該問題提出了異常檢測大模型AnomalyGPT。AnomalyGPT利用大模型的強大語義理解能力,通過精心設計的圖像解碼器和提示嵌入微調方法,能夠讓大模型充分理解工業場景圖像,判斷其中是否含有異常部分並指出異常位置,在少樣本和無監督工業場景中取得了業內最好性能,有利於基礎大模型的行業落地。

AnomalyGPT為了解決現有大模型缺乏特定領域知識和局部細節理解較弱這兩個問題,設計了提示學習器和圖像解碼器兩個模組,對現有的大模型進行訓練調整,方法結構如下圖所示:
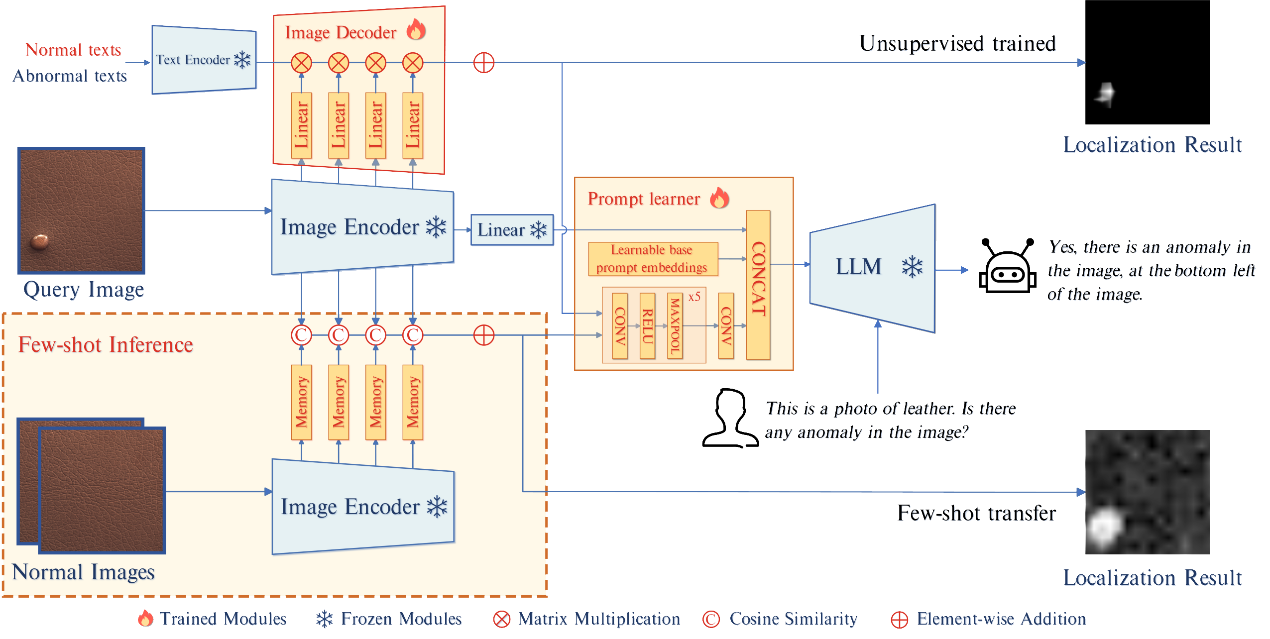
1.圖像解碼器:該模組參考多模態大模型的特徵對齊思路,通過若干個線性投影層,將圖像編碼器所提取的由淺至深的中層特徵與分別代表正常和異常語義的文本特徵對齊。該結構能夠提供異常區域分割的注意力圖,通過將該注意力圖輸入到大模型中,能夠指導大模型關注圖像中異常概率較高的局部區域,為大模型提供視覺細節資訊。
2.提示學習器:該模組包含一個6層的卷積神經網路,用於將圖像解碼器輸出的注意力圖轉化為大模型能夠理解的提示嵌入向量,通過提示嵌入的方式對大模型進行微調,可以為大語言模型提供異常檢測所需的領域知識,同時有效避免大模型産生災難性遺忘問題。
此外,為了對大模型進行訓練,研究團隊還提出來使用基於泊松圖像編輯的異常模擬方法來産生模擬異常數據,如下圖所示,相比于傳統的剪切拼接方法,泊松圖像編輯模擬産生的異常更加自然,這進一步提高了AnomalyGPT方法的性能。

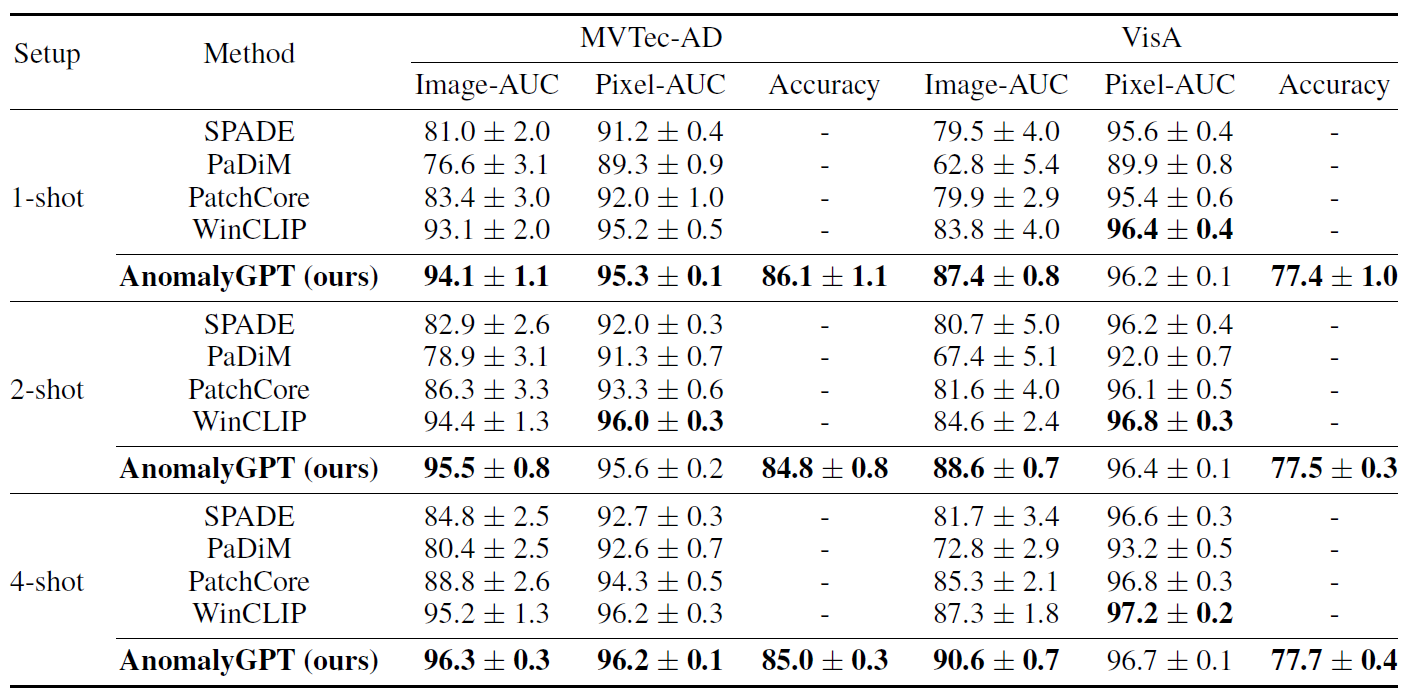
基於上述方法結構,AnomalyGPT研究團隊在兩個最權威的工業異常檢測數據集 MVTec-AD和VisA上進行了實驗,與現有少樣本異常檢測方法相比,AnomalyGPT取得了業內最先進的性能,實驗結果如下表所示:
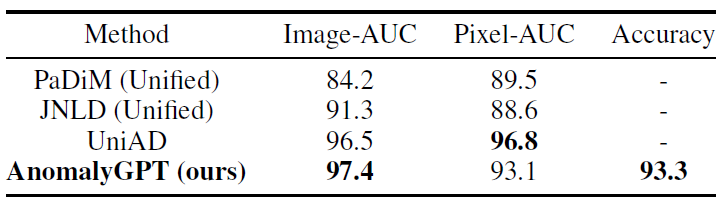
在無監督設置下,AnomalyGPT也取得了業內最高的性能,結果如下表所示:
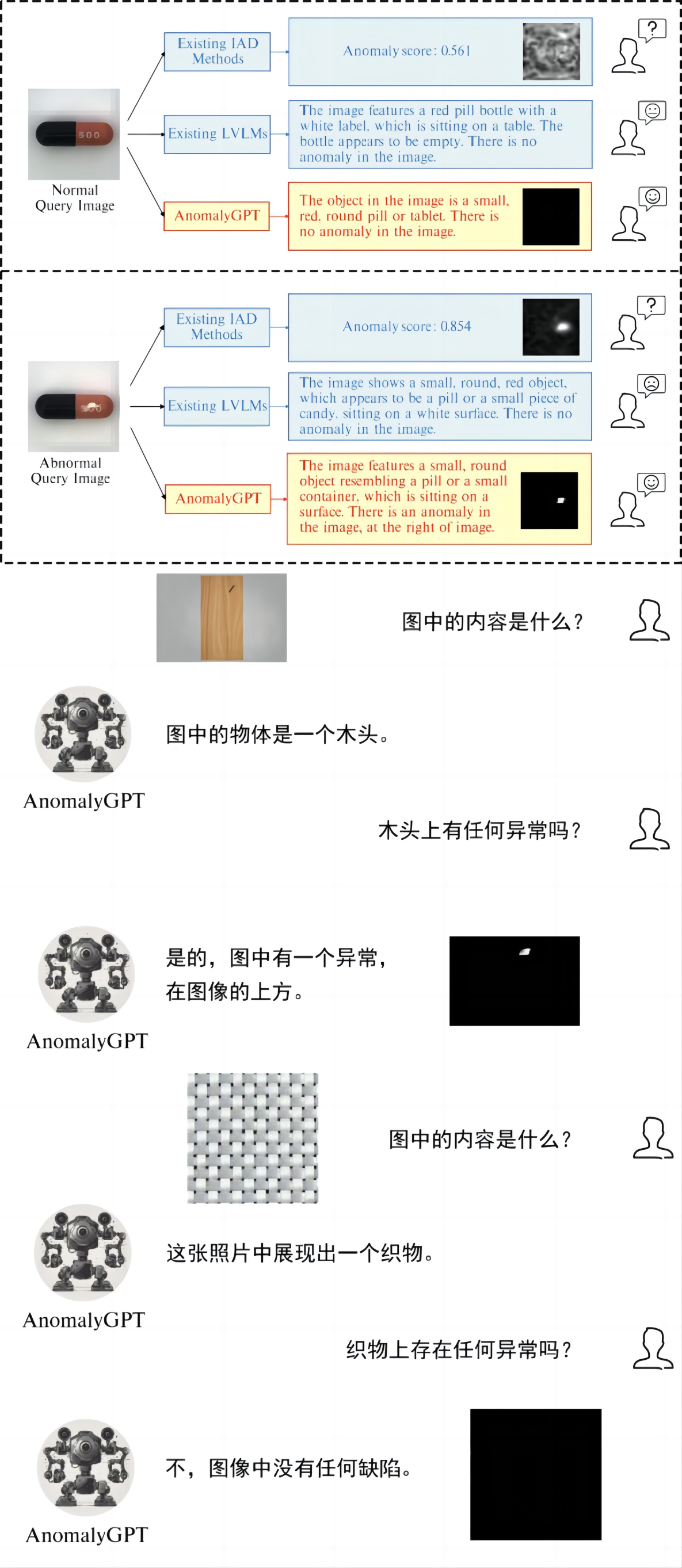
下圖展示了AnomalyGPT在一些實例上的異常檢測和定位結果,與現有的大模型相比,AnomalyGPT在圖像內容理解和異常檢測與定位任務上都具有更好的表現:
AnomalyGPT論文已經被人工智慧頂級會議 AAAI 2024接收,論文預印版已發佈于 Arxiv上,並開源了相關代碼和演示頁面。
研究團隊認為,現有的大模型在通用領域表現卓越,但是在工業、醫學等專業領域的表現相對較弱,如何設計相應結構和方法,提高大模型的行業應用能力,是一個值得深入研究的問題。