租個4090顯示卡,讓你的大模型推理快到飛起!
發佈時間:2024-04-12 14:01:16 | 來源:中國日報網 | 作者: | 責任編輯:趙茜當前人工智慧如火如荼的發展帶動了很多技術革新,其中的大語言模型已經成為一個熱門的研究領域,不僅吸引了眾多學術界的研究者,也讓技術應用領域的開發者們躍躍欲試。但是在大模型的開發方面,有一個重要的因素——那就是顯示卡的不同,竟然可以在模型訓練的效率和效果上造成顯著的差異。
有人説,AI時代下,算力就是一切,然而算力的基礎就是加速卡。但市面上的加速卡型號也非常的多,如何從品質參差不齊的眾多加速卡中選出適合大模型推理的“王炸卡”就顯得格外重要了,那麼就不得不説RTX 4090這款加速卡了,GPU核心的整合程度驚人,小小晶片上GPU核心整合了數千個CUDA核心,以及大量的張量核心和RT核心,計算速度可以達到數Teraflops(萬億次浮點運算每秒)的級別。為用戶提供了強大的計算能力,為大模型訓練的速度更上一層樓。
根據官方數據,4090加速卡採用的是Ada架構,對比前幾代來説,計算速度更快,算力更強,搭載的24G大顯存,有效解決了顯存不夠的情況。同時在圖像處理方面也有不錯的表現。
另外,在大語言模型的訓練上,由於大模型的複雜性和數據量的增加,對各種軟體的支援需求也被提上了日程。 4090加速卡在這方面有著顯著的優勢,它支援廣泛的軟體生態,包括CUDNN庫,CUDA工具包,同時也支援各種主流的深度學習框架,TensorFlow,PyTorch等。
很多科研人員在訓練大模型的過程中,大型語言模型需要處理數十億甚至數百億的參數,需要大量的計算資源來進行權重更新和優化。面對這個需求痛點,4090顯示卡的高性能計算單元和並行處理能力就可以高效地執行這些計算任務,加快模型的收斂速度,並提高訓練效率。
4090加速卡不僅僅是針對個人用戶,還面向高校科研人員、以AI技術為驅動的藥物研發等企業。那麼對於不同用戶來説,應該從哪些渠道獲得4090加速卡呢?無非只有兩種途徑,一是土豪版的買買買,但弊端是會面臨資産貶值,各種維護和管理問題。二是經濟版的租賃4090加速卡,可以找雲服務商租用GPU雲主機,這樣即免去了維護管理問題,還實現了花小錢辦大事的目的。
不過在逛了幾家主流雲服務商的官網後發現,可供選擇的加速卡型號少之又少。這裡給大家推薦一個源於超算背景的雲服務商,那就是北京超級雲計算中心,其背後竟然有中國科學院的背景,可謂妥妥的實力派。
不僅如此,北京超級雲計算中心的算力資源也非常豐富,提供包括H800、H100、A800、A100、V100、4090、3090、L40S等,並且表明瞭預置市場上的主流框架環境,實現了開箱即用。除此之外,其GPU加速卡有多種形態的産品,包括超算架構的大規模集群形態,以及擁有root許可權資源專享的雲主機形態,以及裸金屬形態。
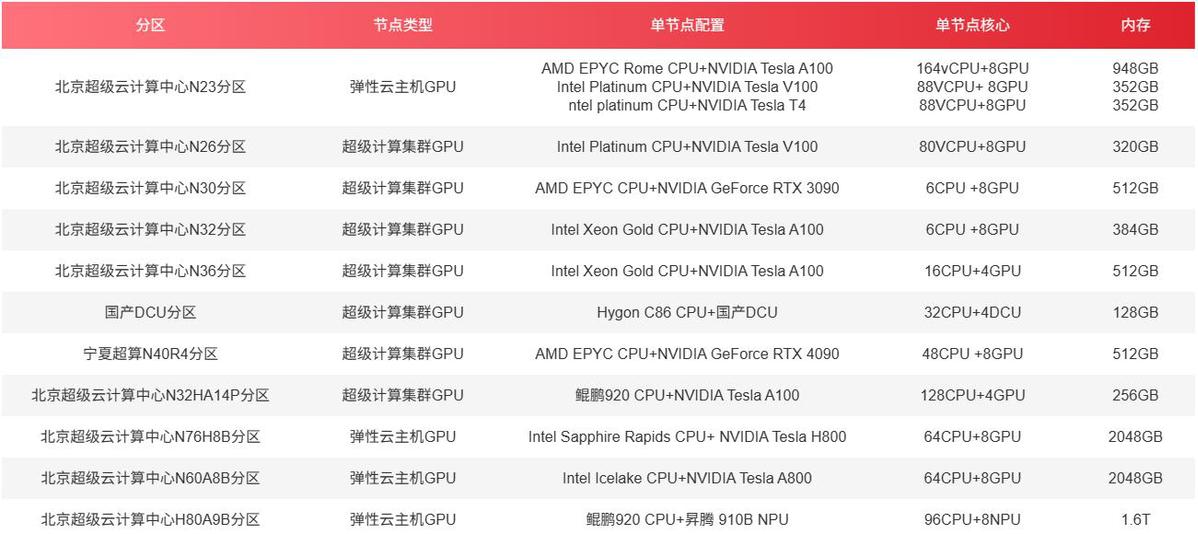
那對於用戶來説應該選雲主機模式,還是集群模式?這個要看用戶的具體需求來判斷,兩種模式相比各有優劣,雲主機使用模型更偏向於普通電腦,從操作下,入手難度都非常的簡單,但雲主機相比集群模式的劣勢也非常明顯,雲主機主要開機就會進行計費。而集群模式的計費就更加靈活,僅對計算過程中實際消耗的GPU時間和數量收費。計算任務完成後,計費即停止,確保用戶僅支付實際計算費用。並且集群模式採用共用網路頻寬,不單獨向租戶收取網路費用,減輕了用戶的成本,並且安裝軟體的過程不産生任何費用。但是集群模式也有其劣勢,那就是採用的linux系統,需要通過命令集的形式完成相關的任務,對於沒有電腦基礎的用戶不是很友好。
總的來説,人工智慧的快速發展,算力是基礎,好的算力不僅依賴好的顯示卡,還要真正實現用戶從可用、好用到降本。
