阿裏首次公佈自然語言處理成果
發佈時間:2017-07-20 16:25:17 | 來源:機器之心 | 作者:佚名 | 責任編輯:胡俊業界普遍認為,自然語言處理是人工智慧中最難的部分,也是決定 AI 是否「智慧」的關鍵因素。王成龍在接受機器之心採訪時説,「阿里巴巴在語音交互技術方面已經深耕多年,並已在多類産品中應用。
針對這篇論文,該團隊向機器之心發佈了獨家技術解讀:
語義編碼的意義
自然語言這一被人類發明的信號系統,通常被我們歸為一種「非結構化數據」。其原因在於,自然語言文本是由一堆符號(token)順序拼接而成的不定長序列,很難直接轉變為電腦所能理解的數值型數據,因而無法直接進行進一步的計算處理。語義編碼的目標即在於如何對這種符號序列進行數值化編碼,以便於進一步地提取和應用其中所蘊含的豐富資訊。語義編碼是所有自然語言處理(Natural Language Processing,NLP)工作的「第一步「,同時也很大程度地決定了後續應用的效果。
傳統的文本編碼方式通常將其當作離散型數據,即將每個單詞(符號)作為一個獨立的離散型數值,如 Bag-of-Words (BOW)、TF-IDF 等。但是這類方法忽略了單詞與單詞之間的語義關聯性,同時也難以對單詞的順序及上下文依賴資訊進行有效編碼。近幾年,深度學習技術被廣泛的應用於 NLP 領域,並在眾多演算法命題上取得了突破。其本質在於,深度神經網路在特徵提取(語義編碼)上具有極大的優勢。
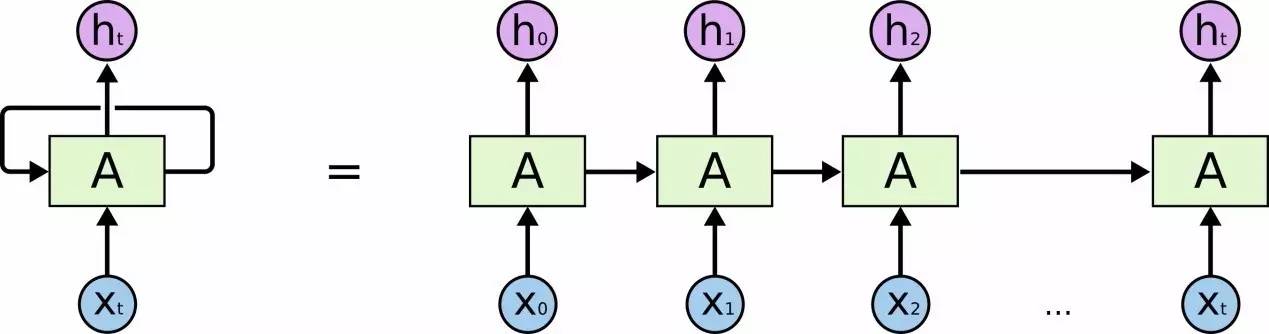
已有方法的瓶頸
當前,較為常用的文本語義編碼模型包括迴圈神經網路(Recurrent Neural Network,RNN)以及卷積神經網路(Convolution Neural Network,CNN)。